Your task manager is the best agent memory you're not using.
Not because vector databases are bad. Because the store everyone builds for their agent starts rotting the day they stop feeding it. And the one knowledge base you feed every single day, you never plugged in.
Picture the failure. Your agent opens a fresh session and asks what it already asked yesterday. Meanwhile your task app holds years of context: curated, prioritized, deduplicated, pre-ranked by the most reliable ranker there is. You. Highest retrieval power, almost no upkeep, sitting one quadrant away from every memory tool you've tried.

You Already Built the Store
Agent memory without a vector database means the agent reads from a store you already keep current, not a new one you have to feed. Most projects build something new: a vector DB, a bespoke framework, a fresh pile of markdown only the agent sees. Your task app is none of those. You keep it fed without trying.
You already maintain a knowledge base by hand. Every day. It has your deployment runbook, the decision you made about that client, the reason you abandoned an approach in March. It is sorted into projects, tagged, dated, and pruned. Nobody calls it agent memory. That is exactly what it is.
The hard part of memory was never storage. It was curation. And you've been doing the curation for years, in an app you trust, for reasons that have nothing to do with AI.
The Store That Rots
A vector database as agent memory is a second brain that only the agent reads. It starts empty. You write an ingestion script. It captures what the script thought to capture. Then reality moves, and the store doesn't, because re-feeding it is one more chore on a list you already ignore.
That's the trap in the bottom-right of the map. Real retrieval power, but bolted on the side, drifting from the truth a little more each week. Powerful and separate. Separate is the word that kills it.
Memory files have the opposite problem. No retrieval at all. The whole file gets injected every session, so it has to stay small, so it can't hold much. Manual and limited.
The Empty Corner
Every memory tool trades one thing for the other. Real search costs upkeep. Zero upkeep costs search. So three corners fill up, and the fourth, durable and powerful, sits empty because nothing earns it.
The way into that corner is not a better database. It's an adapter. Keep the app you already live in. Give the agent a fast, structured, two-way channel into it. The upkeep stays zero because you were already paying it. The retrieval gets real because the channel does hybrid search, dense plus sparse plus keyword, fused and ranked, with provenance on every hit.
The Handoff Outlives the Chat
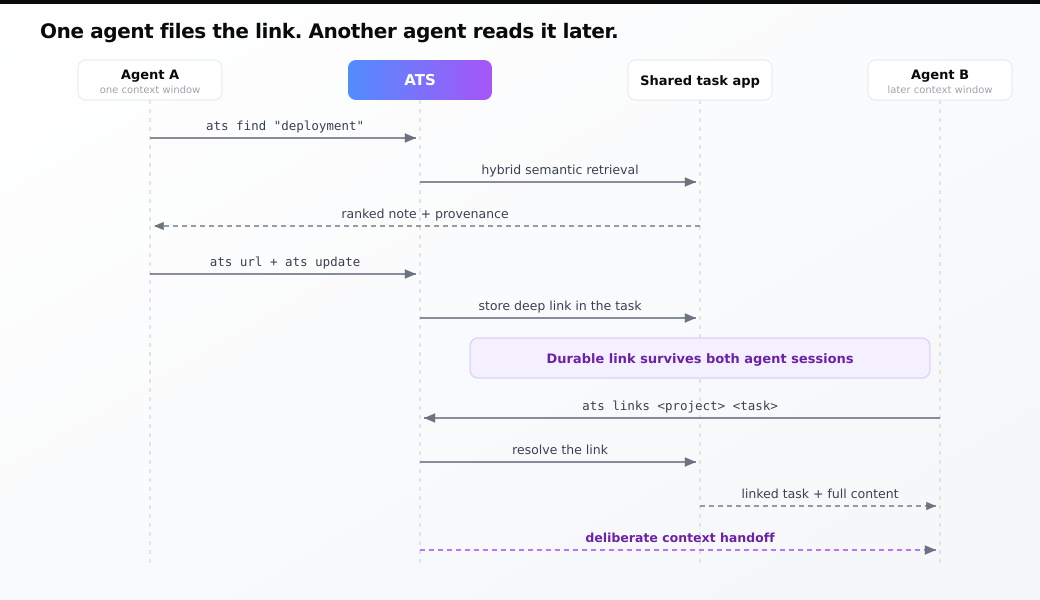
Retrieval gets you the right note. Links get you something a chat history never could. One agent runs a search, turns up a note, and writes a deep link into the task it's working on. A second agent, in a separate context window hours later, follows that link and reads the full context. Neither agent talked to the other. The relationship survived because it lives in the task app, not in a session that gets compacted away.
You Are the Ranker
Here is the part that surprised me in real use. The context comes back curated at write time, not only at read time. Every item is already hung on a theme you care about the moment you capture it. client-work. side-project. The runbook lives next to the project it belongs to because you put it there, not because an embedding guessed.
So retrieval has structure to grab instead of a flat pile to rerank. Three searches collapse into one. The first fetch is the right one, and better context on turn one means a better answer on turn one. No second search, no "let me refine that," no agent quietly burning tokens to rediscover what you already filed.
That's the reframe. The question was never which memory database to build for your agent. The question is which knowledge base you already maintain by hand that your agent still can't see.
Agentic Task System is the open-source answer: an MCP server and CLI that turns the task app you already curate into agent memory, no new database. For the full setup, the task-manager agent memory guide walks the CLI and MCP wiring end to end.
So: what are you curating every day that your agent has never once been allowed to read?
I write field notes from real builds, AI integration, cron-driven automation, and the parts that break in production. New posts every two weeks; if this one was useful, the agent playbook is the companion download.