When Control Becomes Authority: Calibration Governance in STEM BIO-AI 1.7.x
Control slowly becomes authority when nobody marks the boundary.
That is the calibration problem I kept running into while building STEM BIO-AI.
The project began as a deterministic evidence-surface scanner for bio and medical AI repositories. It inspected observable repository surfaces — README files, docs, code structure, CI, dependency manifests, changelogs, and boundary language — and mapped them to a structured review tier.
That was useful.
But the harder problem was not producing a number. The harder problem was preventing every useful adjacent signal from becoming part of that number.
In a bio/medical AI repository review, several lanes can look similar if the tool is not careful:
- deterministic scoring
- diagnostic findings
- replication evidence
- advisory interpretation
- domain-specific review posture
They all matter. But they should not all have the same authority.
The principle behind the 1.7.x calibration work is simple:
easy experimentation, hard drift
Researchers should be able to express review posture. Operators should be able to simulate policy changes. Artifacts should show policy metadata.
But none of that should silently mutate the official score.
Current 1.7.5 Boundary
This post describes the released 1.7.x state as of v1.7.5, not a future authoritative-read-through design.
The formal score currently comes from three weighted score-bearing stages, plus explicit penalty and cap logic:
| Surface | Role |
|---|
| Stage 1 | README / stated evidence boundary |
| Stage 2R | repo-local consistency |
| Stage 3 | code and bio-responsibility surface |
| C1 | hardcoded-credential penalty |
| clinical cap / hard floor | score ceiling or T0 floor when clinical-adjacent boundary rules require it |
Stage 4 exists, but it is a separate replication lane. It reports reproducibility posture without automatically changing the formal score.
In 1.7.5, STEM BIO-AI has implemented calibration architecture, but it remains mostly mirror-only and preview-oriented.
Implemented surfaces include:
- packaged calibration profiles
- schema and runtime validation
- profile identity surfaced in result metadata
stem policy liststem policy explainstem policy derivestem policy simulate- simulation-only local profile files
- profile hashes and read-mode metadata in artifacts
The active named recommendation surface is intentionally narrow:
defaultstrict_clinical_adjacency
reproducibility_first is still a draft posture, not an active release-grade named recommendation.
The key boundary:
the authoritative scan scoring path is still protected from arbitrary user-provided profile mutation.
scan --policy <name> can surface selected profile metadata. policy derive and policy simulate can show governed preview behavior. But user-provided profile files do not become official scoring authority.
More specifically, local profile files are accepted only by stem policy simulate, and the CLI rejects them unless the file remains mirror_only.
That is not a missing convenience. It is the boundary being tested before it is allowed to become authority.
Why Calibration Is Not a Tuning Console
The wrong calibration UX looks like this:
{
"stage_1_percent": 30,
"stage_2r_percent": 25,
"stage_3_percent": 45,
"ca_no_disclaimer_cap": 61,
"b2_partial_credit_mode": "looser"
}
This is editable. But editable is not the same as governed.
Most researchers do not think in raw score constants. They usually know something closer to this:
- clinical-adjacent claims should be treated very strictly
- reproducibility matters strongly in this environment
- README polish should not outweigh code evidence
- a casual mention of "limitations" should not count as meaningful transparency
So the current design starts with posture questions, not raw constants.
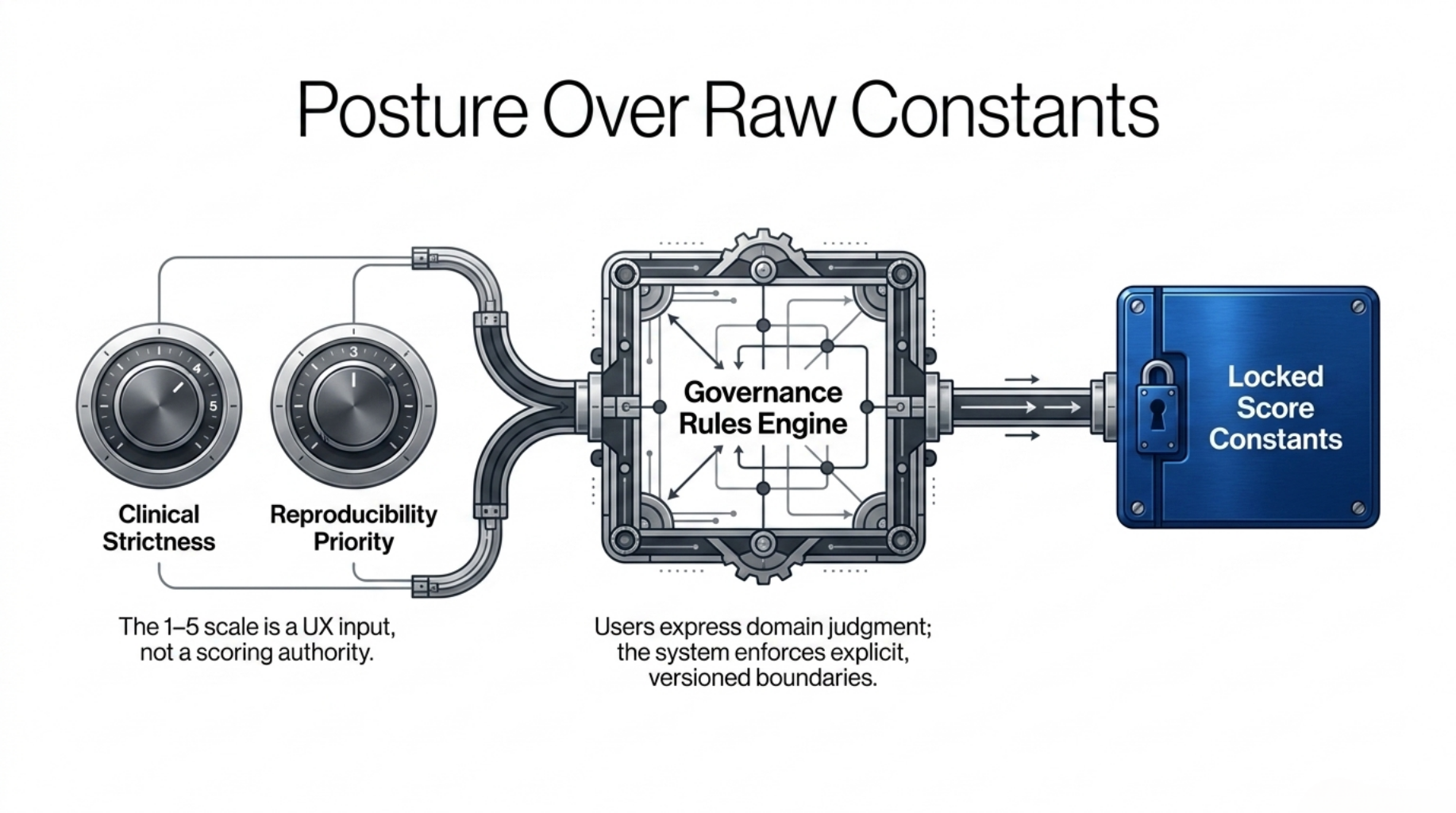
The user-facing intent layer uses a 1–5 scale:
1 = minimal emphasis3 = moderate emphasis5 = very strong emphasis
The important rule:
the 1–5 scale is a UX input surface, not part of the formal score engine.
Users can express clinical strictness, code-integrity priority, reproducibility priority, and structured limitations requirements. But those answers do not directly become score constants.
They pass through an explicit rule table:
| Condition | Outcome |
|---|
clinical_strictness >= 4 and reproducibility_priority <= 3 | recommend strict_clinical_adjacency |
all four values are 2 or 3 | keep default |
| no named-profile rule matches | generate preview_only bounded deltas |
This table is not an empirically optimized model. It is a conservative governance rule table.
The threshold choices are design-steward decisions, not claims of statistical optimality. Their purpose is to keep the translation layer narrow, reviewable, and non-authoritative until a stronger benchmark-backed promotion process exists.
For example:
clinical_strictness = 4
reproducibility_priority = 4
This does not automatically recommend strict_clinical_adjacency.
It falls back to preview_only, because two strong postures are competing and no release-grade named profile currently resolves that conflict.
A hidden similarity function might look more flexible. It would also be harder to audit.
What the CLI Is Allowed to Do
The preview workflow can look like this:
stem policy derive \
--clinical-strictness 5 \
--code-integrity-priority 4 \
--reproducibility-priority 3 \
--structured-limitations-requirement 4
or:
stem policy simulate /path/to/repo --profile-file my_profile.json
But those flows are not the same as:
stem scan /path/to/repo --stage1-weight 0.35 --cap 72
The first two are governed preview surfaces. The last one is an untracked tuning console.
The design supports the first and rejects the shape of the last.
That is the practical meaning of easy experimentation, hard drift.
What Actually Gets Verified
The central claim is not:
the current calibration rules are perfect.
The claim is narrower:
calibration changes should not become score authority without a visible governance path.
That can be checked by asking whether the system blocks or exposes the relevant mutation paths:
| Drift risk | Expected control |
|---|
| arbitrary score tuning | no free-form CLI weight / cap override |
| hidden profile mutation | profile status and read mode surfaced |
| unclear profile identity | profile name, version, and hash visible |
| advisory influence leakage | advisory output cannot override final_score |
| reproducibility overcompensation | replication_score does not change formal_tier |
| premature named-profile expansion | ambiguous postures fall back to preview_only |
| detector promotion drift | detector policy is versioned in policy files and governance docs, though not yet first-class per-detector artifact metadata |
This is not a full empirical benchmark. It is a governance verification target: the policy cannot quietly become authoritative without leaving a trace.
That trace is stronger for some surfaces than others. Profile identity, hash, and read mode are already artifact-visible in 1.7.5. Detector promotion semantics are versioned and documented, but not yet surfaced as first-class per-detector policy metadata in the result object.
The B2 Tightening Example
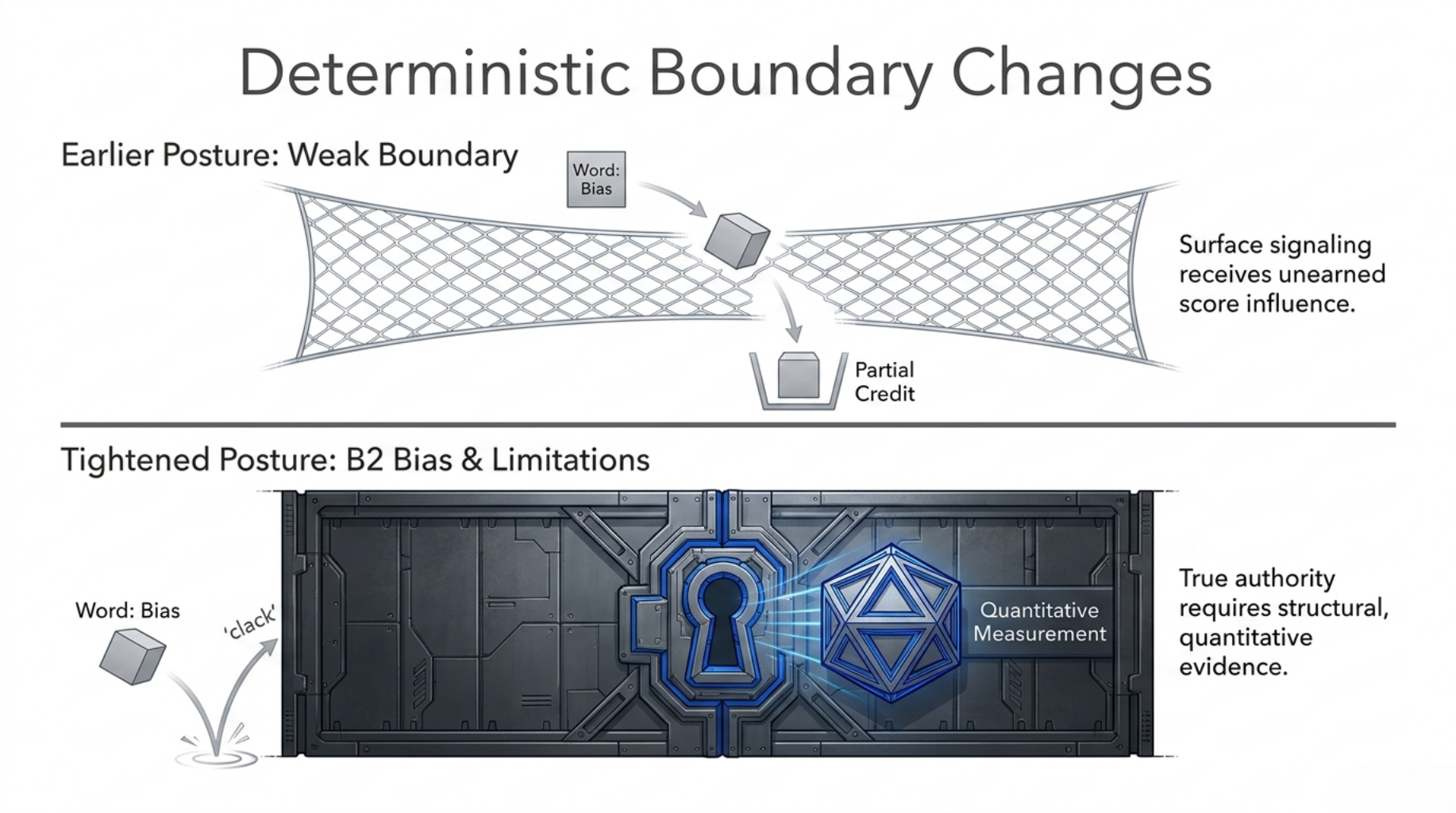
The clearest scoring example is Stage 3 B2: the bias and limitations measurement surface.
Earlier behavior allowed a weaker boundary: a simple vocabulary-level signal could still receive partial credit.
That became too permissive. A repository that mentions "bias" or "limitations" once is not necessarily disclosing a meaningful boundary. It may only be surface signaling.
So the B2 rule became stricter:
| Case | Earlier posture | Tightened posture |
|---|
| no bias / limitations vocabulary | 0 | 0 |
| minimal single-term mention only | partial credit possible | 0 |
| structured limitations language | partial credit possible | partial credit possible |
| quantitative measurement evidence | full credit possible | full credit possible |
The rule change creates a concrete score-path difference:
a repository that previously depended only on a minimal single-term limitations mention no longer has a B2 partial-credit path after the tightening.
That is the current public claim.
I am not presenting a benchmark-wide before/after score delta here, because that would require a pinned fixture set and published comparison protocol. Without that, a claimed "T3 became T2" example would be anecdotal at best.
So the honest evidence level is rule-level impact:
- the credit path changed
- the changed path is deterministic
- the changed path is inspectable
- benchmark-level deltas should be published only when the fixture protocol is pinned
In clinical-adjacent repositories, limitation language is not decoration. It is part of the claim boundary.
Why Stage 4 Stays Separate

The strongest counterargument is fair:
If reproducibility is important, why does it not affect the formal score?
My answer is that importance and score authority are not the same thing.
Stage 4 measures replication posture: containers, reproducibility targets, dependency locks, artifact references, seeds, citation surfaces, and similar evidence.
Those signals matter.
But they do not mean the same thing as the formal claim boundary.
A repository can be highly reproducible and still make unsafe clinical claims. It can have clean containers while lacking a clinical-use disclaimer. It can be easy to rerun while still having weak data provenance or shallow limitation language.
If Stage 4 lifted the formal score too early, reproducibility could compensate for claim-boundary weakness.
That would be a different scoring philosophy.
It may become valid in the future, but only if the rule is explicit.
For now, Stage 4 remains separate because reproducibility should be visible and review-relevant without silently overriding the formal score boundary.
That is why stronger reproducibility intent currently falls back to preview_only instead of becoming a release-grade named profile.
Advisory AI Uses the Same Boundary
Advisory AI follows the same rule.
Helpful interpretation is not score authority.
STEM BIO-AI can export provider-neutral advisory packets and validate downstream advisory responses, but the deterministic scanner does not need an external model runtime to produce the formal score.
Unless a future release explicitly changes the policy, advisory output remains structurally subordinate to the deterministic score.
The broader advisory boundary is a separate topic.

The 1.7.x transition is best understood as a shift in questions:
| Earlier scoring-tool question | Audit-workflow question |
|---|
| What score did the repository get? | Which policy profile was visible when the score was produced? |
| Which stage contributed most? | Was that stage score-authoritative, diagnostic, or separate-lane evidence? |
| What evidence triggered the tier? | Did the evidence change the formal score or only the review posture? |
| What should the user fix? | Would a proposed policy change be preview-only, experimental, benchmark-candidate, or release-authoritative? |
The score still matters.
But the system is increasingly designed around the custody of the score: where it came from, what was allowed to influence it, and what was intentionally kept outside it.
What This Still Does Not Do
STEM BIO-AI still does not:
- validate biomedical efficacy
- certify benchmark truth
- determine clinical deployment safety
- let advisory AI overwrite the formal score
- open arbitrary numeric tuning in the official scan path
- allow profile experimentation to become official policy without governance
Those are not missing conveniences. They are boundaries.
A strong repository evidence tier is still an observable repository-surface signal. It is not clinical clearance, regulatory approval, or proof of biomedical validity.
The Next Version Direction
The next important step is not adding more knobs.
It is authoritative policy read-through in parity mode:
- the default policy profile becomes the source read by the scoring path
- existing fixtures should show no score or tier drift
- policy hashes remain visible in artifacts
- non-default and researcher-provided profiles remain governed preview surfaces until promoted
- score-affecting policy changes become explicit release events
This is not a big-bang rewrite.
It is authority relocation.
The goal is to move score-affecting constants into versioned policy objects without changing the score by accident.
Final Position
The calibration problem is not really about giving users more control.
It is about deciding when control becomes authority.
If every useful signal can gradually influence the score, the score stops being an audit artifact.
It becomes a negotiation.
That is what STEM BIO-AI is trying to avoid.
Researchers should be able to express posture. Operators should be able to simulate alternatives. Policy stewards should be able to promote changes.
But the formal score should not move unless the governance path says it moved.
That is the difference between a tuning console and an audit system.