A governance engine should not pretend to know the truth of every domain.
That was the architectural lesson behind CGF.
At Flamehaven Labs, we build B2B governance engines for highly regulated environments. Over the past year, we developed specialized deterministic systems for different review contexts:
- CareChainGovernanceEngine (CCGE): a fail-closed clinical-governance engine for enforcing safety-oriented review gates in bio-AI workflows.
- The Analyst's Problem Framework (TAP): a “Proof Custody” engine designed to package and audit mathematical proof candidates.
Both worked inside their own domains. But both also exposed the same architectural problem: reusable custody mechanics were mixed with domain-specific decision semantics.
We needed to audit new targets — such as external open-source intake, RAG retrieval receipts, and AI evolution proposals. If we did not extract a common, domain-neutral kernel, we would be doomed to rewrite the entire scanning, hashing, and reporting pipeline for every new vertical.
The result was the Custody Governance Framework (CGF): a domain-neutral custody kernel for B2B technical review workflows.
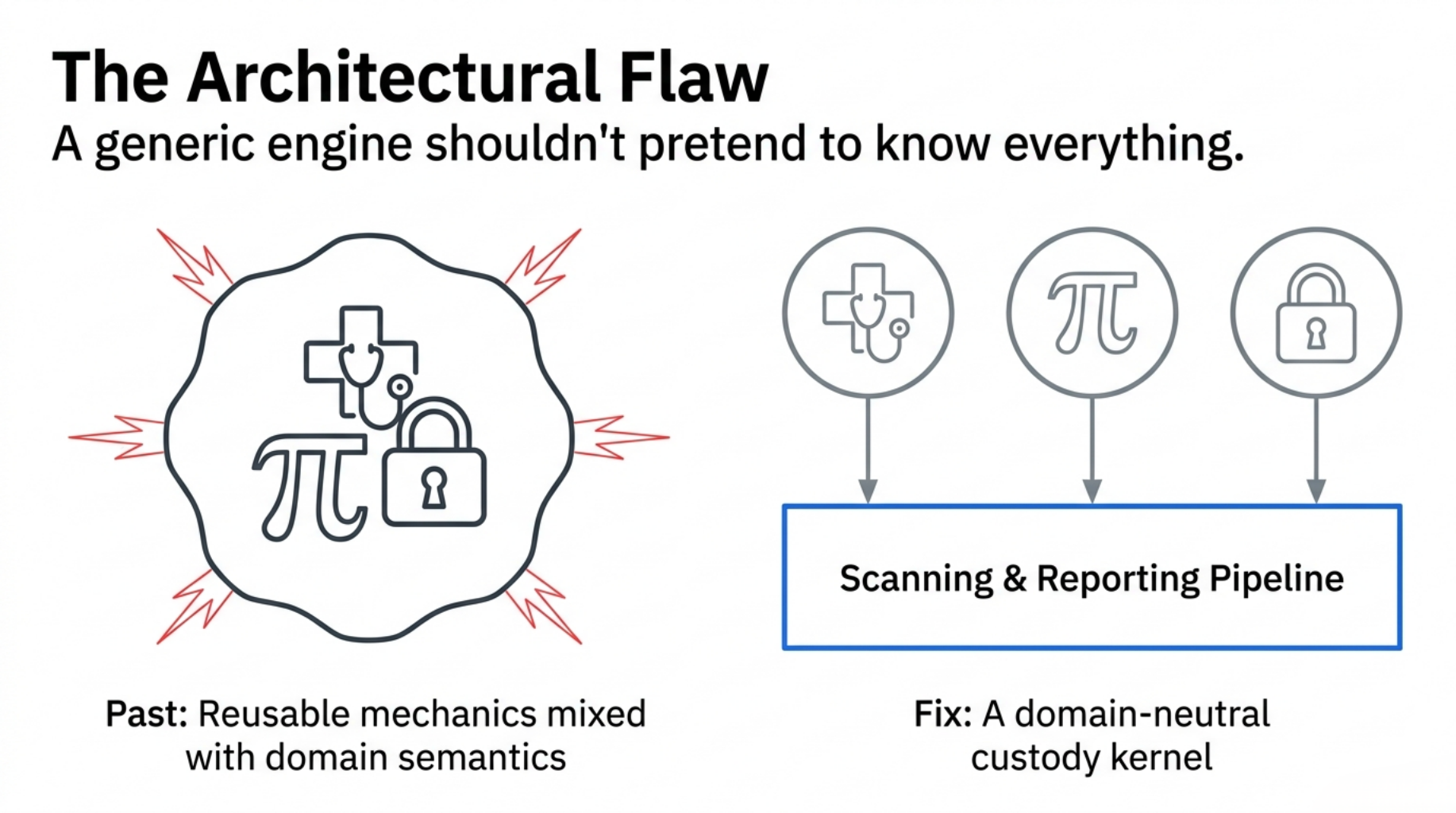
This is an architecture extraction note on how we decoupled domain truth from custody mechanics, the API design that powers it, and why we specifically rejected the modern trend of “LLM-agentic” governance.
The Problem with “Agentic” Governance
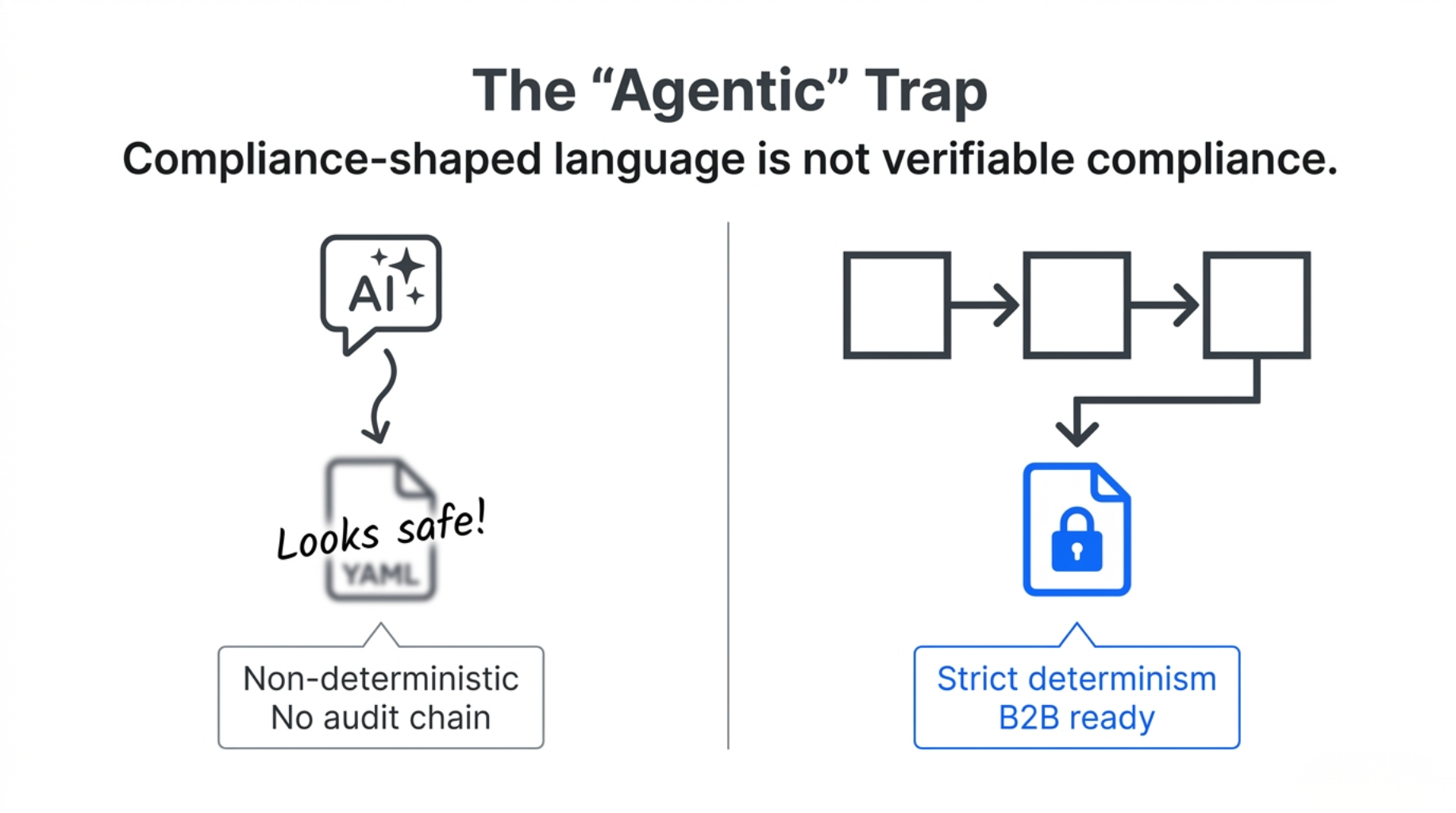
Many emerging AI governance workflows are becoming document-shaped or agent-shaped: a YAML file, a Markdown policy, or an LLM prompt that says, “check whether this is safe.”
The problem is not that LLMs are useless. The problem is that they can produce compliance-shaped language without producing verifiable compliance artifacts.
In a strict B2B handoff — where auditability, legal review, and future regulatory mapping to frameworks such as the EU AI Act or NIST AI RMF may matter — you cannot rely on non-deterministic evaluations.
CGF takes the opposite approach: strict determinism.
The framework does not own domain-truth semantics. It owns the custody mechanics around findings, profiles, evidence, approvals, and artifacts.
The Architecture: A Deterministic Data Flow
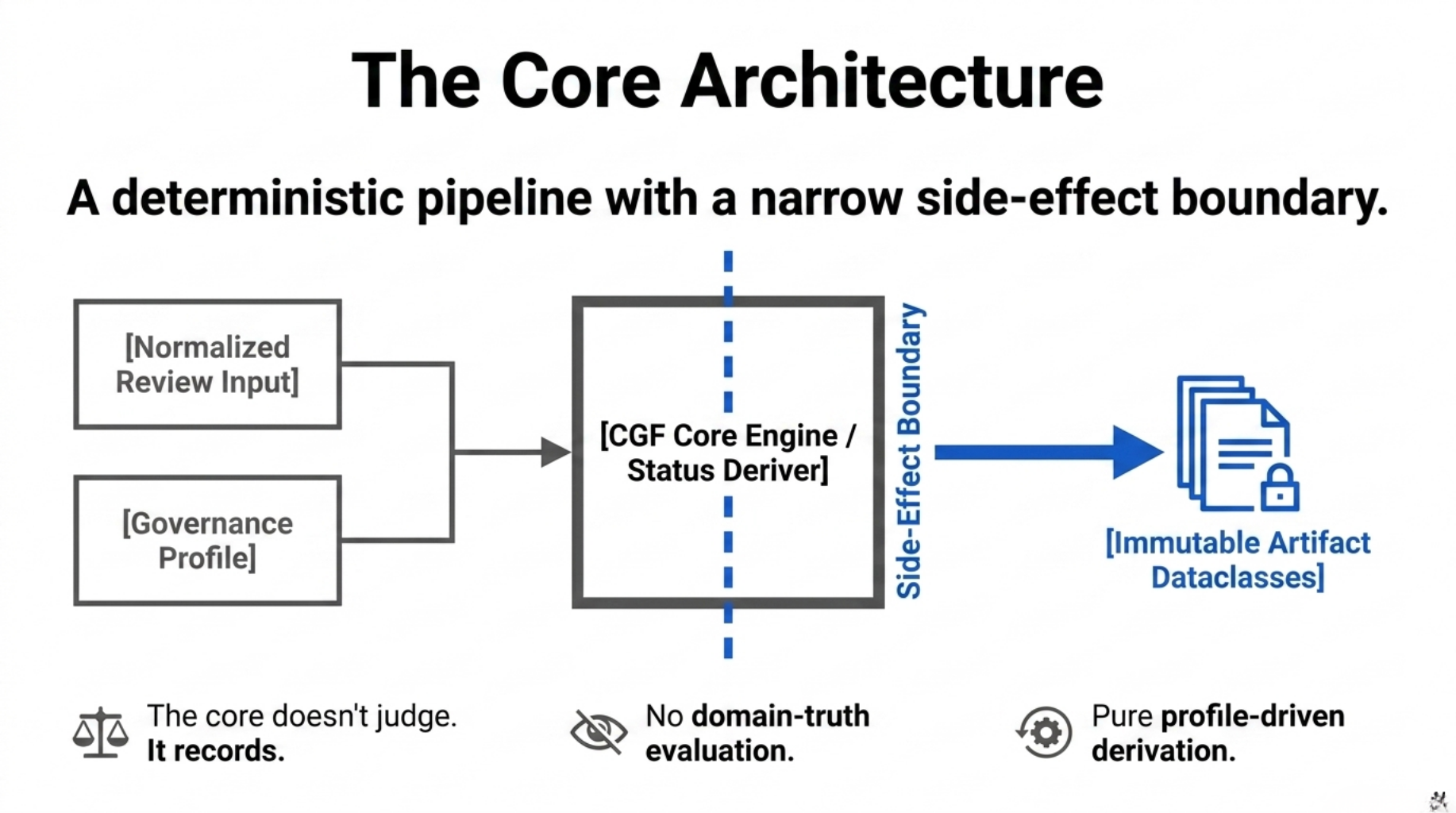
To enforce this separation, we designed CGF as a deterministic pipeline with a narrow side-effect boundary.
The core engine takes a normalized review input and a GovernanceProfile, transforming them into immutable artifact dataclasses. The writer layer then materializes those objects as files, manifests, and release artifacts.
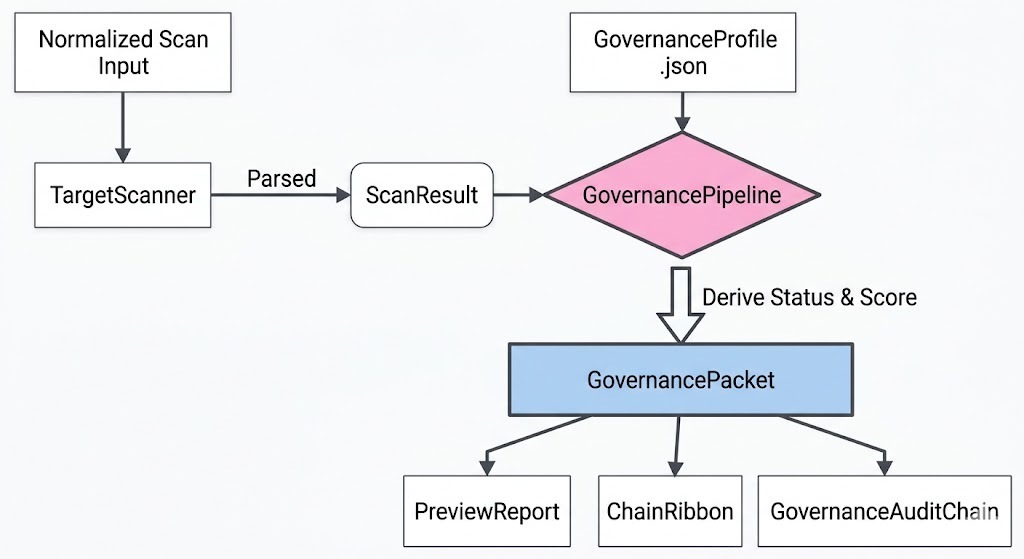
Here is what the end-to-end flow looks like:
The API Boundary
At the core boundary, the framework does not evaluate whether a finding is “bad” by its own logic.
It relies on a StatusDeriver driven by the injected profile.
A simplified sketch of the boundary looks like this:
# Simplified sketch, not the full implementation
@dataclass(slots=True)
class GovernancePipeline:
profile: GovernanceProfile
status_deriver: StatusDeriver
def build_packet(self, result: ScanResult) -> GovernancePacket:
# 1. Inject profile-specific requirements, such as mandatory surfaces
governed_result = self._with_profile_requirements(result)
# 2. Derive deterministic status via the profile
status_result = self.status_deriver.derive(governed_result)
# 3. Assemble the immutable packet
return GovernancePacket(
target=governed_result.target,
profile_id=self.profile.profile_id,
status=status_result.status,
status_reason=status_result.reason,
findings=list(governed_result.findings),
evidence=list(governed_result.evidence),
compliance_score=_compute_compliance_score(governed_result.findings),
)
The exact implementation also handles timestamps, approval bridges, validation, artifact writing, and manifest verification.
The important point is architectural: the core does not decide domain truth. It records how a profile interpreted the evidence.
Architecture Highlight 1: Inspectable Artifacts Over Silent Mutation
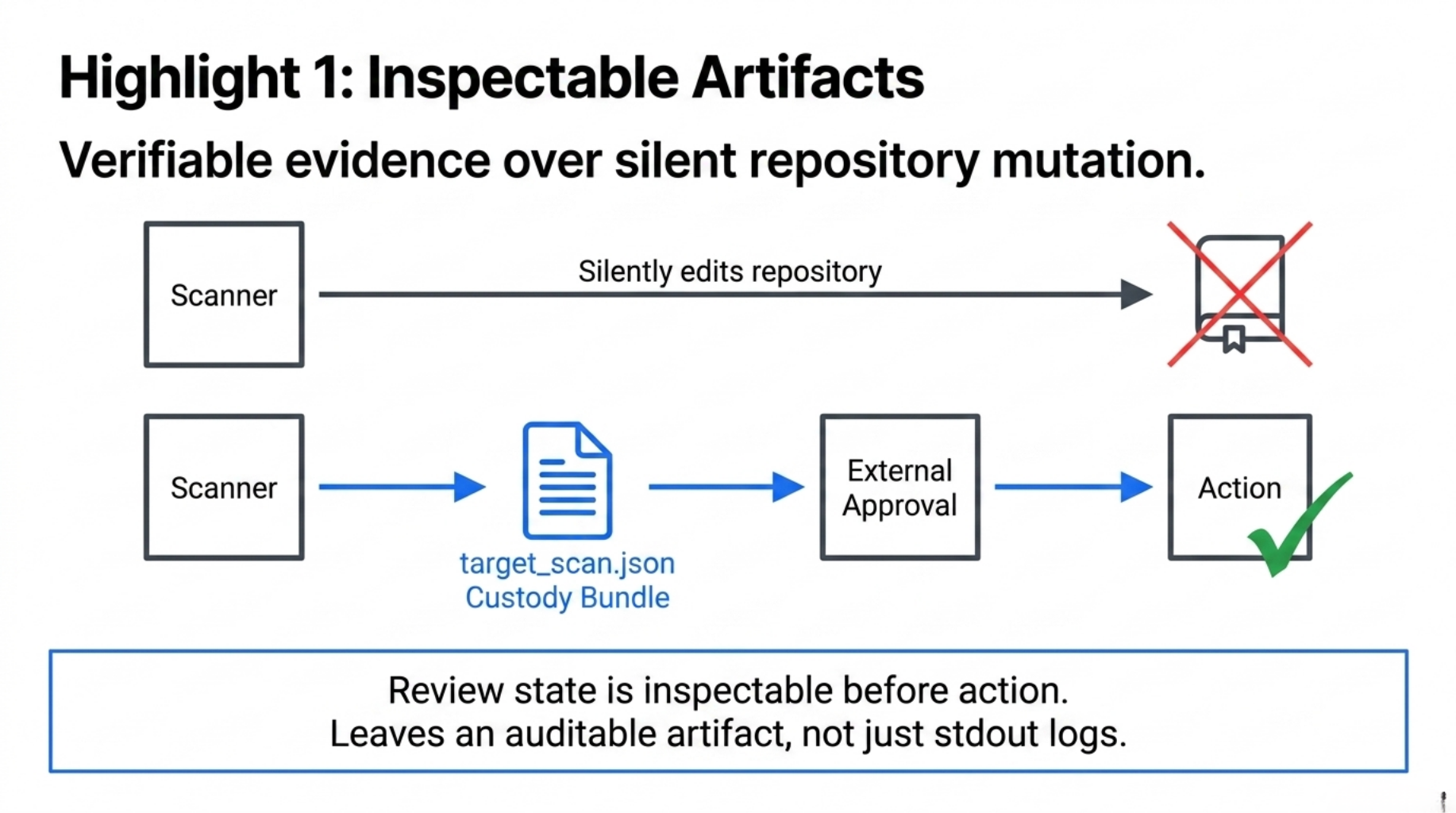
A major risk in governance automation is the engine silently mutating the target repository, for example by automatically injecting compliance boilerplate.
Many tools solve this with a --dry-run flag that prints logs to stdout.
In a B2B audit, stdout logs are not enough. You need an auditable, verifiable artifact.
CGF implements a preview-first artifact flow. When the pipeline runs, it does not mutate the target repository by default. Instead, it consumes a normalized review input and emits a deterministic custody bundle:
$ cgf run --profile proof_custody.json --scan target_scan.json --out audit/
In real deployments, target_scan.json may be produced by a vertical adapter, repository scanner, RAG receipt processor, or customer-specific intake layer.
The output is an inspectable custody bundle:
audit/
├── governance_packet.json # Machine-readable audit state
├── preview_report.md # Human-readable summary
├── chain_ribbon.md # Markdown tag for custody-chain review state
└── manifest.json # Artifact manifest with file hashes
The important point is not that CGF edits the repository.
It does not.
The important point is that the review state, findings, proposed next actions, and artifact hashes become inspectable before any external system decides what to do next.
Architecture Highlight 2: The Reality of Audit Chains
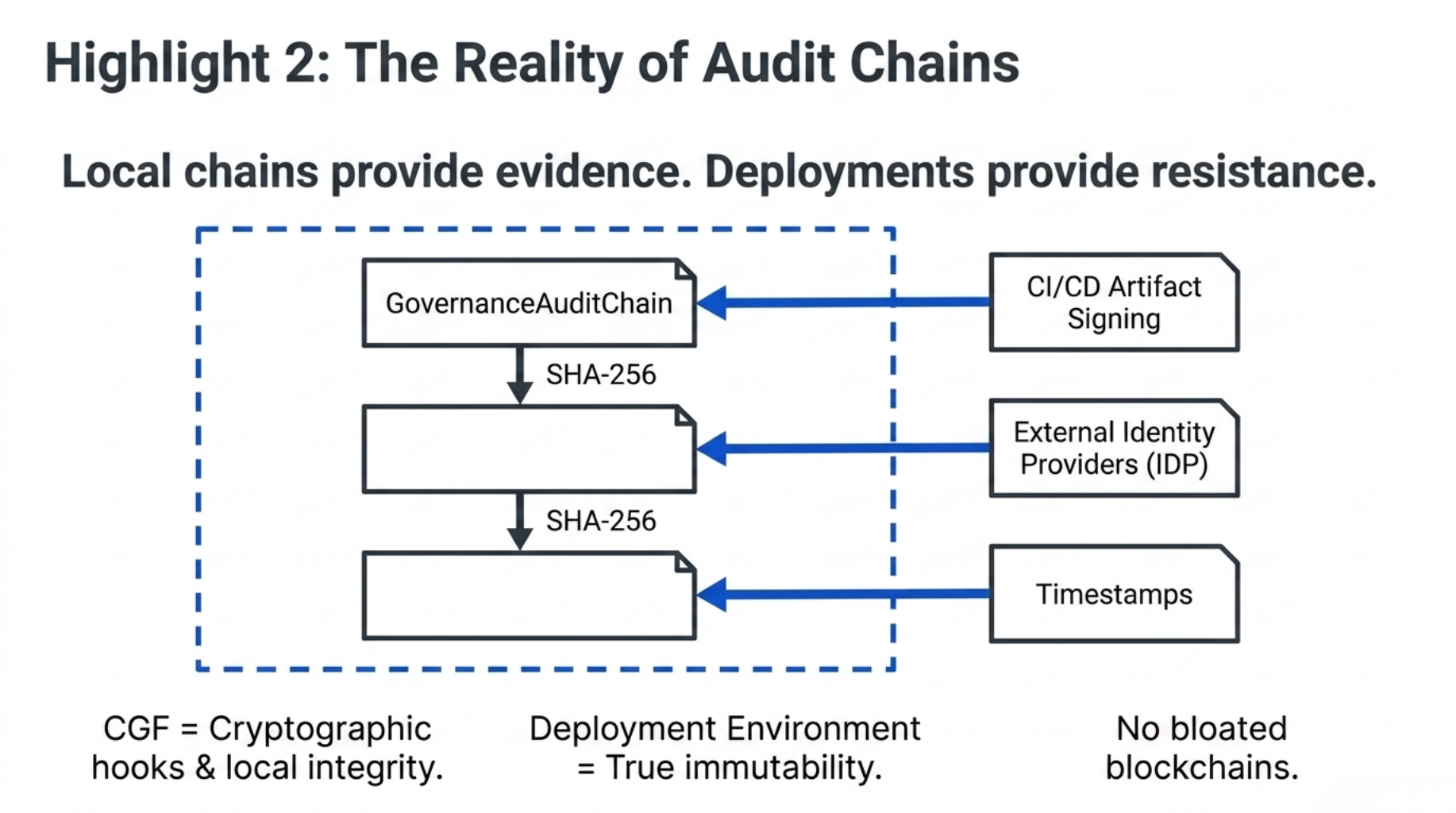
In B2B handoffs, customers often ask for tamper-resistance.
CGF supports a GovernanceAuditChain, an append-only JSONL ledger where packet records can be linked through SHA-256 hashes.
But we need to be honest about the tradeoff:
Local hash chains are tamper-evident, not tamper-resistant.
If a bad actor has write access to the filesystem, they can delete the audit directory and regenerate the entire chain from scratch.
CGF does not use a blockchain. The cost and complexity of a distributed ledger would outweigh the benefits for local repository scanning.
Instead, CGF provides local tamper-evidence.
To achieve true tamper-resistance, the deployment environment still matters: CI/CD artifact signing, external timestamping, identity providers, or customer-controlled archival systems.
For example, an external identity token can be wired into an approval bridge:
# Wiring an external identity token into the local chain
bridge = ApprovalBridge(
state="approved",
approved_by="compliance_lead_JWT_subject",
notes="Cryptographic signature from Identity Provider XYZ",
)
approved_packet = GovernancePipeline.apply_approval(packet, bridge)
The framework provides the cryptographic hooks and chronological integrity.
The deployment environment provides the immutability.
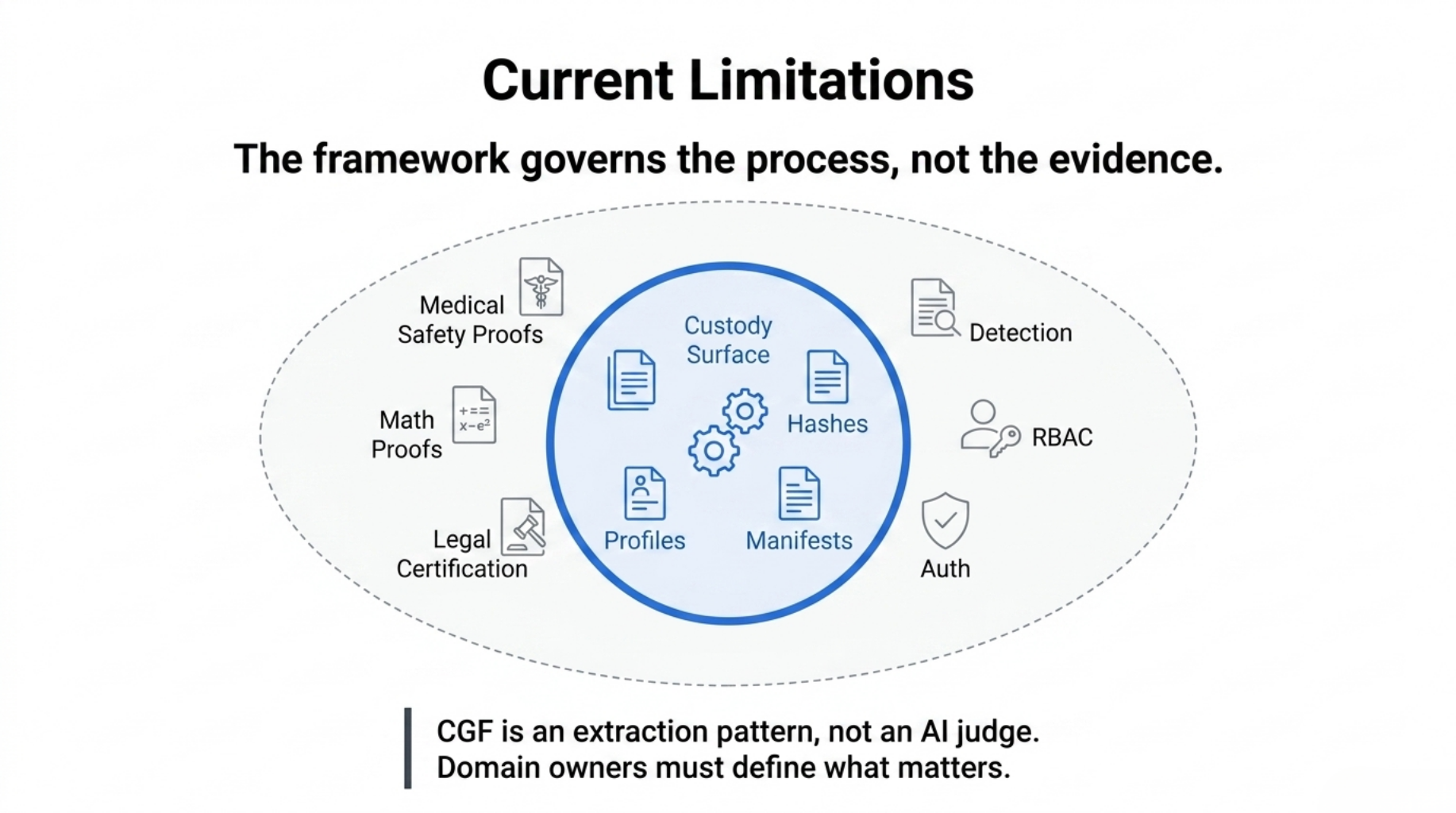
Current Limitations
This post is not a release announcement or a regulatory certification claim.
It is an architecture note about the extraction pattern: how we separated reusable governance mechanics from domain-specific truth semantics.
CGF is still early. It is not a compliance platform, not a hosted governance service, and not a regulatory certification product.
That distinction matters.
CGF does not prove that a medical system is safe. It does not prove that a mathematical argument is true. It does not certify legal compliance. It does not replace domain experts, auditors, clinicians, lawyers, or reviewers.
What it does is narrower, but more concrete:
It makes the custody surface inspectable.
There are also practical limitations.
As mentioned, local hash chains are tamper-evident, not tamper-resistant. True immutability still has to come from the deployment environment: CI/CD signing, external timestamping, identity providers, or customer-controlled archival systems.
CGF is also not yet a complete enterprise governance platform. Authentication, RBAC, multi-tenant profile registries, async approval workflows, and regulatory citation mapping are still roadmap items, not solved infrastructure.
Each domain still needs adapters, profiles, thresholds, and human review policies.
The kernel provides the custody mechanics. The domain owner still has to define what evidence matters.
That is intentional.
A generic governance kernel should not pretend to know the truth of every field.
Roadmap
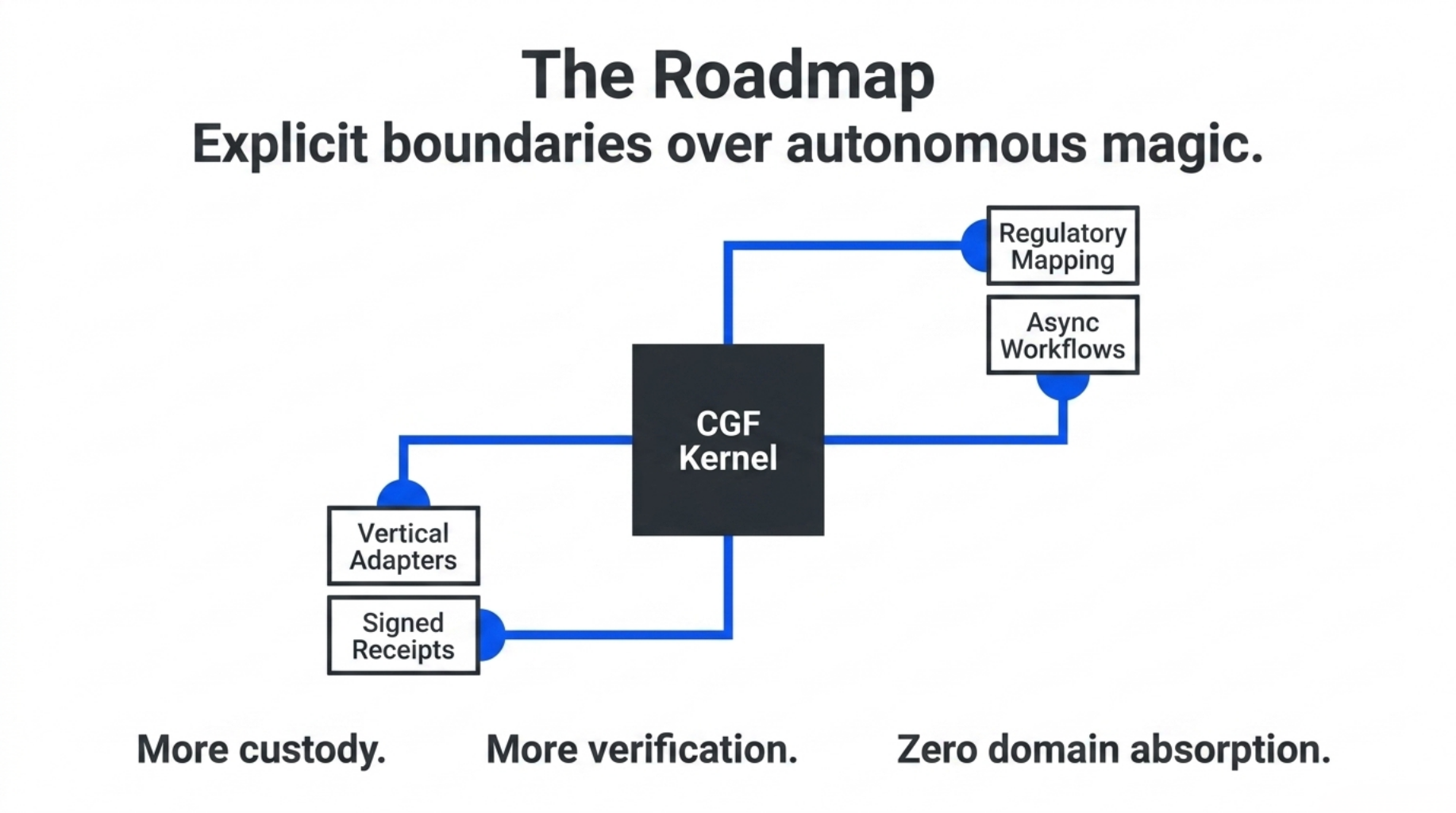
The roadmap is not to turn CGF into a giant all-knowing compliance agent.
The roadmap is to keep the kernel small, deterministic, and inspectable while adding stronger boundaries around the places where real B2B workflows need them.
The next layers are:
- Regulatory mapping: mapping finding codes to frameworks such as the EU AI Act, NIST AI RMF, and ISO/IEC 42001 without turning CGF itself into a legal authority.
- Approval policy hardening: adding stronger policy checks around
ApprovalBridge so approvals can be scoped, expired, and externally verified.
- Async approval workflows: allowing human review, compliance sign-off, or customer approval to arrive after the initial custody packet is generated.
- Profile registries: supporting versioned, tenant-scoped governance profiles so different customers can use different policies without changing the kernel.
- Signed external receipts: allowing RAG systems, technology scanners, quality engines, and external tools to produce receipts that CGF can verify and attach.
- Vertical adapters: binding existing domain systems back to the kernel without importing their domain-specific truth semantics into the core.
Every roadmap item has to preserve the same rule:
The kernel may govern custody, but it must not absorb domain truth.
The direction is deliberately conservative: more custody, more verification, more explicit boundaries — not more autonomous magic.
Why This Matters
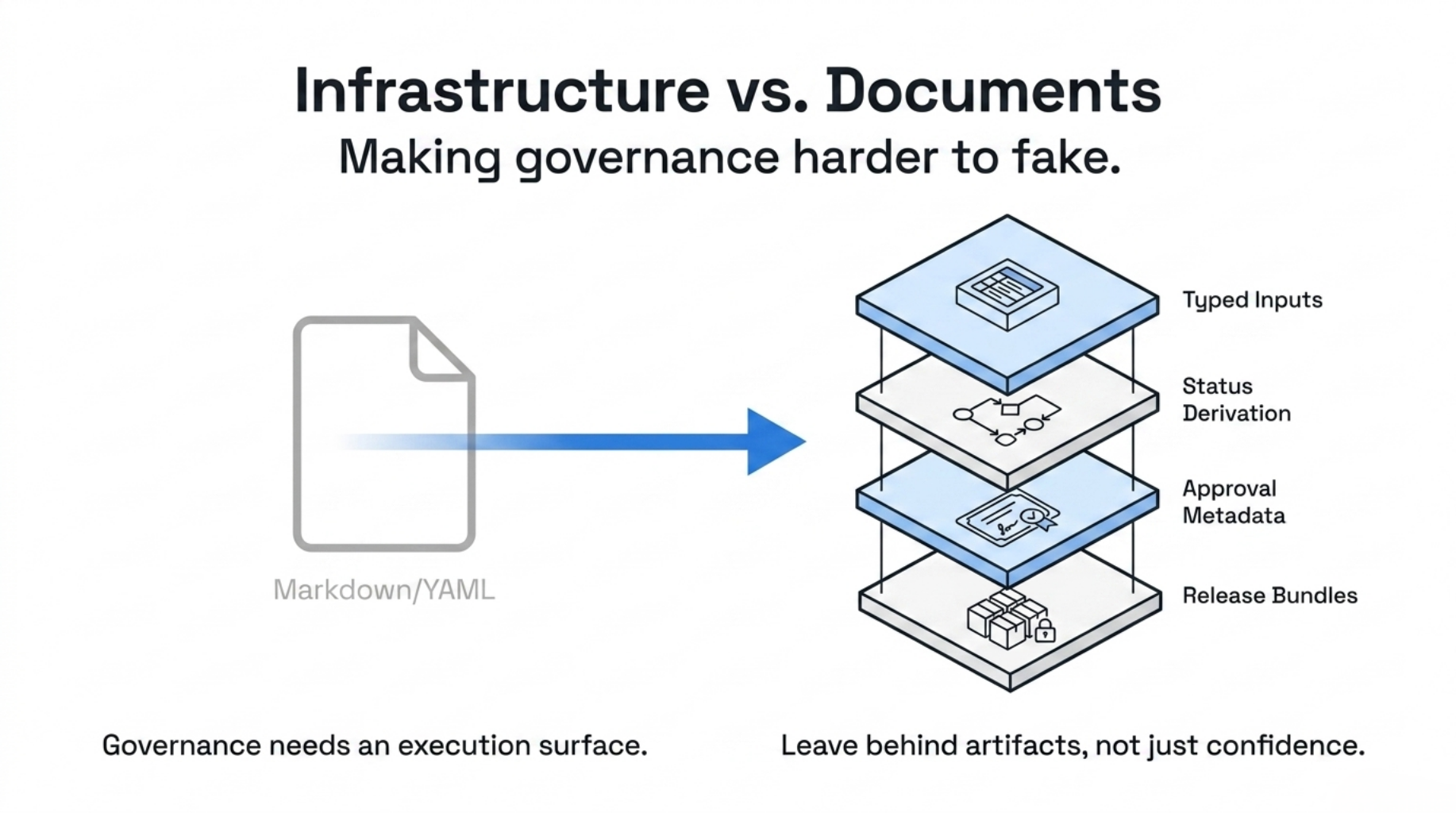
A lot of AI governance today is still document-shaped.
A policy lives in Markdown. A checklist lives in YAML. A prompt says the system should be safe, transparent, aligned, compliant, or human-reviewed.
Those documents are not useless. They are often necessary.
But they are not governance by themselves.
Governance becomes real only when it has an execution surface:
- a typed input boundary
- normalized findings
- profile-owned status derivation
- explicit evidence references
- generated review artifacts
- manifest hashes
- approval metadata
- release bundles
- verification commands
- clear non-goals
That is the difference CGF is trying to make.
It is not another Markdown file describing how governance should work.
It is a deterministic custody pipeline that turns review inputs into inspectable artifacts.
The goal is not to make governance sound more sophisticated.
The goal is to make it harder to fake.
A governance system should leave behind more than confidence.
It should leave behind artifacts.
Conclusion
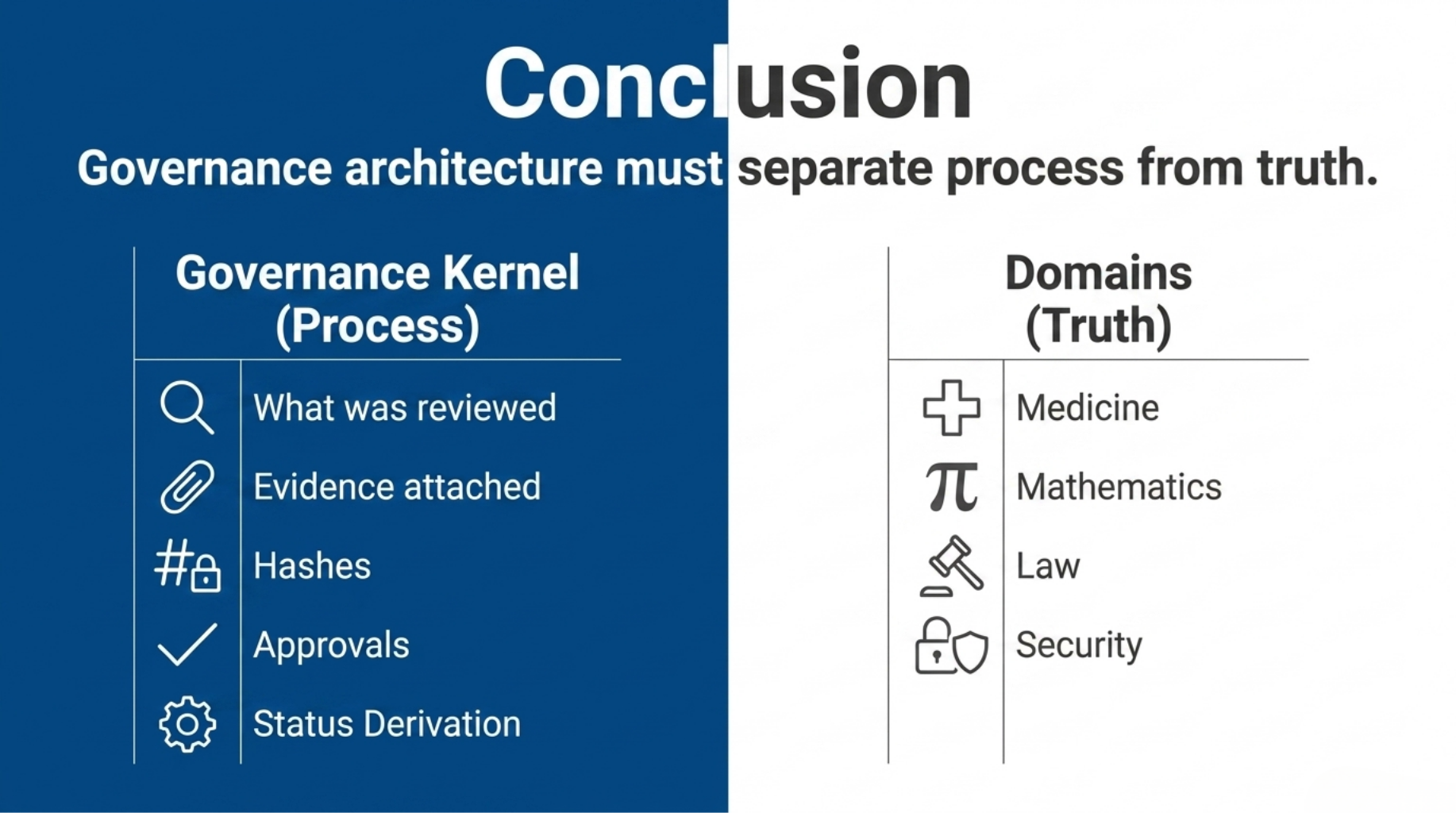
Extracting the Custody Governance Framework taught us that governance architecture has to separate process from truth.
Truth belongs to domains:
- medicine
- mathematics
- law
- security
- finance
- science
Process belongs to the governance kernel:
- what was reviewed
- which profile was applied
- which findings fired
- what evidence was attached
- what status was derived
- who approved it
- whether the resulting artifacts can be verified later
That separation is the reason CGF exists.
It does not try to be an AI judge. It does not ask an LLM to guess whether a system is compliant. It does not hide governance inside a prompt, a policy document, or a YAML file.
It creates custody artifacts that can be inspected.
For us, that is the real boundary between governance as language and governance as infrastructure.