Edge-Native i18n with Astro & Cloudflare Workers - Part 3
In a previous article, I made a claim: translations are data, not code. Your Worker shouldn't care whether you support two languages or fifty. Fixing a typo in a German heading shouldn't require a software release.
This is a condensed version of a full technical deep-dive. The complete implementation - including production wrangler tail logs, the full fetcher.ts and bundle-translations.ts walkthrough, DX considerations, and a six-axis trade-off framework - is available at edgekits.dev.
I built an architecture around that claim. Translations live in Cloudflare KV. A SHA hash of the entire translation bundle - TRANSLATIONS_VERSION - bakes into the Worker as a build-time constant and embeds into every cache key:
const cacheId = `${PROJECT.id}:i18n:v${TRANSLATIONS_VERSION}:${lang}:${namespaces.join(',')}`
The theory: change a translation, regenerate the hash, and all old cache entries become addressed by a stale key that nothing will ever ask for again. Clean, deterministic, content-driven invalidation.
Then I deployed to production and noticed something uncomfortable.
I wanted to tweak the hero heading on the Spanish landing page. The only way to push that change was npm run i18n:migrate and wrangler deploy. Because the hash constant lived inside the Worker bundle, updating the hash meant rebuilding the entire application - every time, for every translation change.
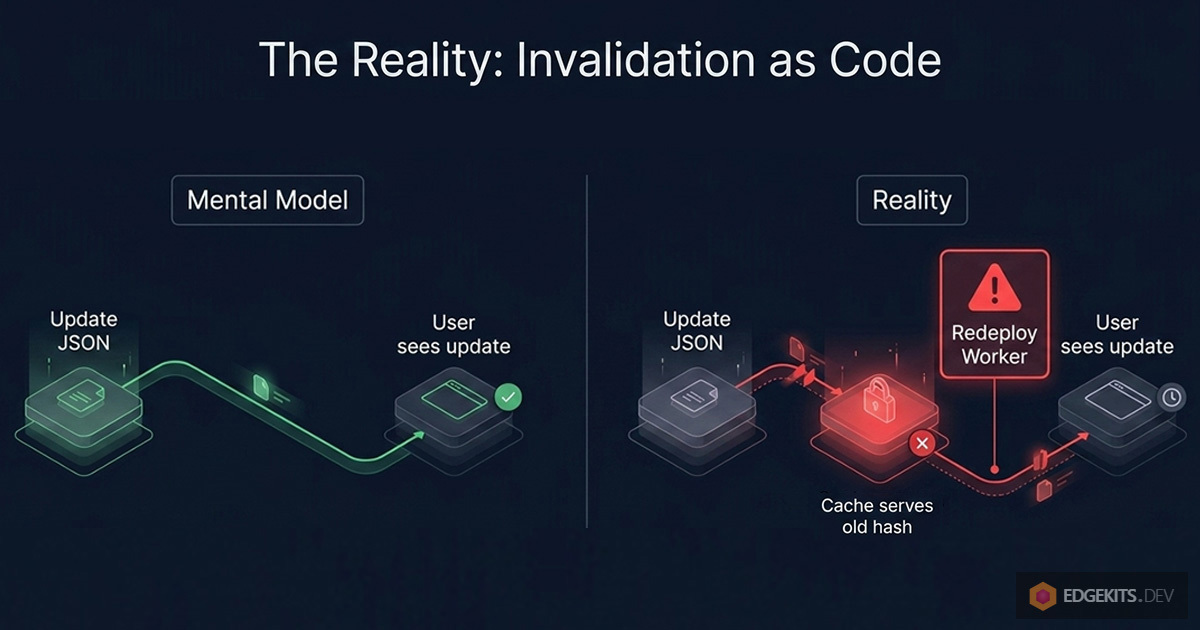
The architecture shipped translations as data. But it invalidated them as code.
The Mental Model Mismatch
Here's what the architecture looked like on paper:
edit JSON → i18n:migrate → users see update
Here's what it actually required:
edit JSON → i18n:migrate → wrangler deploy → users see update
↑
this step is not optional
TRANSLATIONS_VERSION is a constant compiled into the Worker bundle. The only way to change its value at runtime is to rebuild the Worker and redeploy. So the cache keys in production don't change until you ship a new Worker - meaning all existing cache entries keep serving the old content, regardless of what you pushed to KV.
The translation update and the cache invalidation are two physically separate events. One is a KV write. The other is a code deployment. The architecture, despite its elegance, silently requires both.
For a solo project where you control both code and content, this is easy to miss - the deploy happens naturally during the normal development loop. But the moment a non-developer should be able to update translations - a content editor, a translator, a marketing teammate - the coupling becomes a real problem. You can't hand someone a workflow that requires a full application redeploy.
Three Dead Ends
I went through three intermediate approaches before arriving at the right one. The short version:
wrangler deploy --var TRANSLATIONS_VERSION=<hash> looks like it separates the version from the bundle. It doesn't. wrangler.jsonc variables take precedence over CLI flags, so the CLI override is silently discarded. The hash still lives in the bundle.
Version stored in KV, read at request time. This works, but it adds a mandatory KV read to every single request - even fully cached ones. The hot path, which should be a single cache lookup, now becomes a sequential chain: read KV for version, build cache key, check cache. The version KV entry can be cached too, but then you've got a double cache lookup, and the TTL on the version cache becomes a new source of propagation lag.
Version in KV with short TTL. Scales poorly across Cloudflare's global edge. Each of the ~300 edge nodes maintains its own cache independently. A short TTL means each node re-fetches the version on its own schedule, and the propagation window for a content update is bounded by that TTL - not by actual propagation speed. You've traded one coupling for another.
All three approaches share the same underlying assumption: the cache key should carry a version marker, and invalidation happens by rotating that marker. That assumption is the problem.
The Breakthrough: Static Keys + Explicit Invalidation
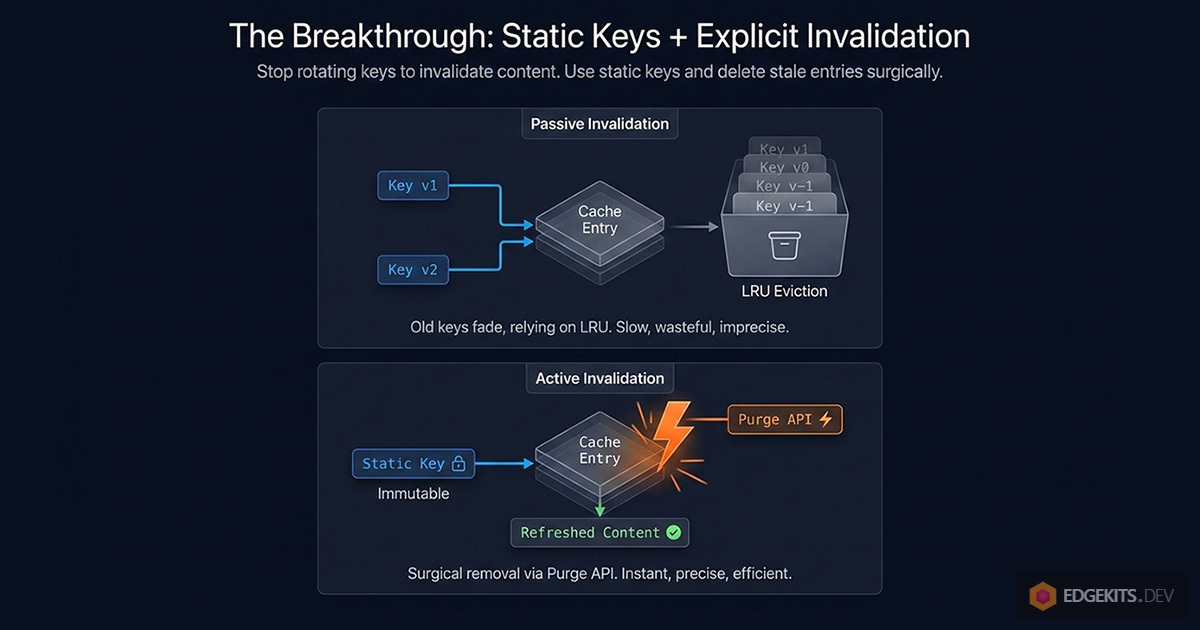
Every dead-end I hit was a variation on passive invalidation: nothing actively removes stale entries; we stop addressing them. The cache fills up with ghosts. Old content drifts around at the edge until Cloudflare's LRU policy decides to evict it.
The alternative is active invalidation: the cache key stays stable across content changes, and when translations update, we explicitly tell Cloudflare to delete the affected entries.
The new cache key shape:
i18n:<locale>:<namespace>
Wrapped into the URL shape that Cloudflare's Cache API expects:
https://<PROJECT.id>/<encoded-identifier>
One key per locale:namespace pair. Stable forever. The same key that stores Spanish landing translations today will store them in a year - whatever version "today" happens to be.
There's a secondary win here. The old architecture cached combined namespace sets: i18n:v<hash>:es:common,landing,newsletter was a single cache entry. A different page requesting common,landing got its own entry - with overlapping content. Same translations, cached multiple times under different keys.
With per-namespace static keys, each namespace is its own cache entry. A page that needs common, landing, and newsletter does three parallel cache lookups. Any other page requesting common gets a cache hit on that namespace - shared across requests, no duplication.
The Hot Path
A user hits /es/blog/some-article. The page needs common, blog, and newsletter. The fetcher issues three parallel cache lookups:
const cacheResults = await Promise.all(
namespaces.map(async (ns) => {
const req = buildTranslationCacheRequest(locale, ns)
const cached = await cache.match(req)
return { ns, data: cached ? await cached.json() : null, hit: !!cached }
})
)
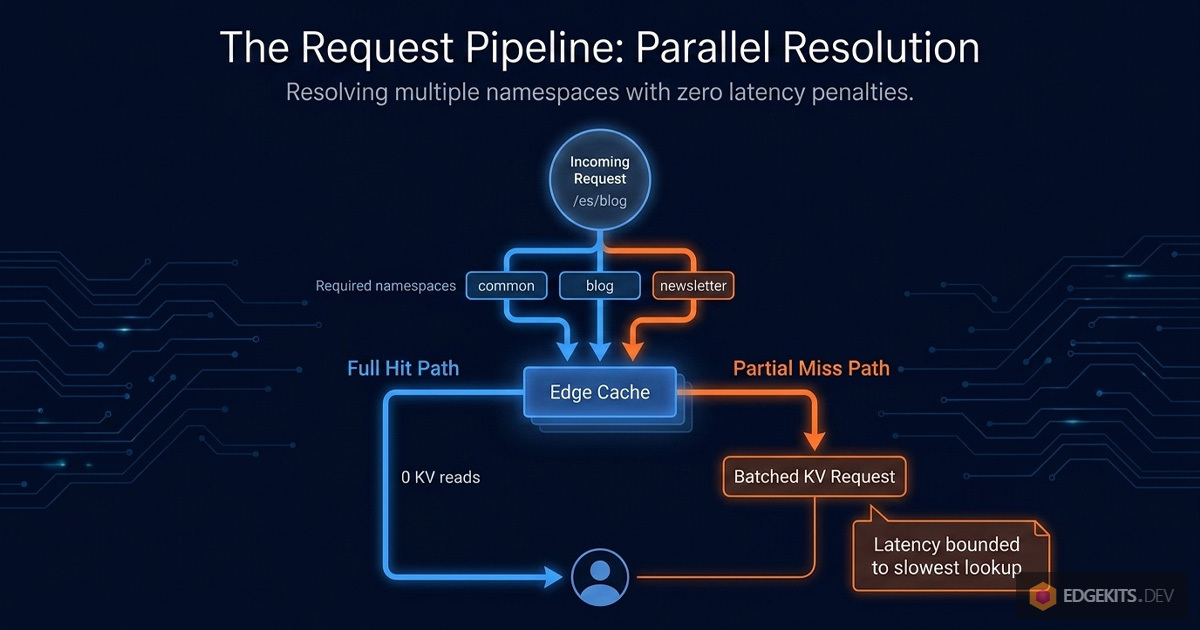
Full hit - all three cached - returns immediately. Zero KV reads.
Partial miss - say blog was recently invalidated - filters down to the missing namespace and issues one KV batch call:
const missing = cacheResults.filter((r) => !r.hit).map((r) => r.ns)
const kvKeys = missing.map((ns) => buildTranslationKvKey(locale, ns))
const kvBatch = await env.TRANSLATIONS.getMultiple(kvKeys, { type: 'json' })
One KV batch regardless of how many namespaces are missing. Results merge with the cache hits, get written back to cache, return.
This is better than both previous architectures on every metric I care about: zero KV reads on the hot path, one batch on partial miss, no cache bloat from combined keys, no version tracking overhead at request time.
The Cloudflare Purge API
If cache keys are stable, how does a translation update ever reach users?
The answer is a Cloudflare platform feature most developers know exists but have never used from code: the Purge API.
The request shape:
POST https://api.cloudflare.com/client/v4/zones/<ZONE_ID>/purge_cache
Authorization: Bearer <API_TOKEN>
Content-Type: application/json
{
"files": [
"https://edgekits.dev/i18n%3Aen%3Alanding",
"https://edgekits.dev/i18n%3Aes%3Alanding"
]
}
You hand it a list of URLs. It returns success and deletes those exact entries from the edge cache, globally, within about a second. The next request to each URL results in a cache miss, the Worker falls through to KV, and fresh content is re-cached under the same stable key.
Notice that the URLs in the purge request are the same URLs used as cache keys. The https://<PROJECT.id>/<encoded-key> shape is shared between cache.put inside the Worker and purge_cache in the migration script. The fetcher writes cache entries under a URL; the migration script deletes them under the same URL. One formula, two contexts. Any drift between them and the purge silently misses - which is why both sides import from the same translations-keys.ts module.
One constraint worth calling out clearly: the Purge API requires your domain to be proxied through Cloudflare - the orange cloud icon in your DNS records. On *.workers.dev subdomains, cache.put silently discards and cache.match always returns undefined. The Workers Cache API is tied to zone-level caching that doesn't exist for the shared subdomain. If your project isn't on a proxied custom domain, this architecture's signature feature is inactive.
Incremental Purging: The Hash File Strategy
Purging every possible locale:namespace URL on every migration run would work but produces a cache stampede - simultaneously invalidating content across all edge nodes triggers a burst of KV reads to re-populate entries that didn't change.
For a project with 5 locales and 10 namespaces, fixing a typo in en/landing.json would purge all 50 cache entries. 49 of those purges are wasted.
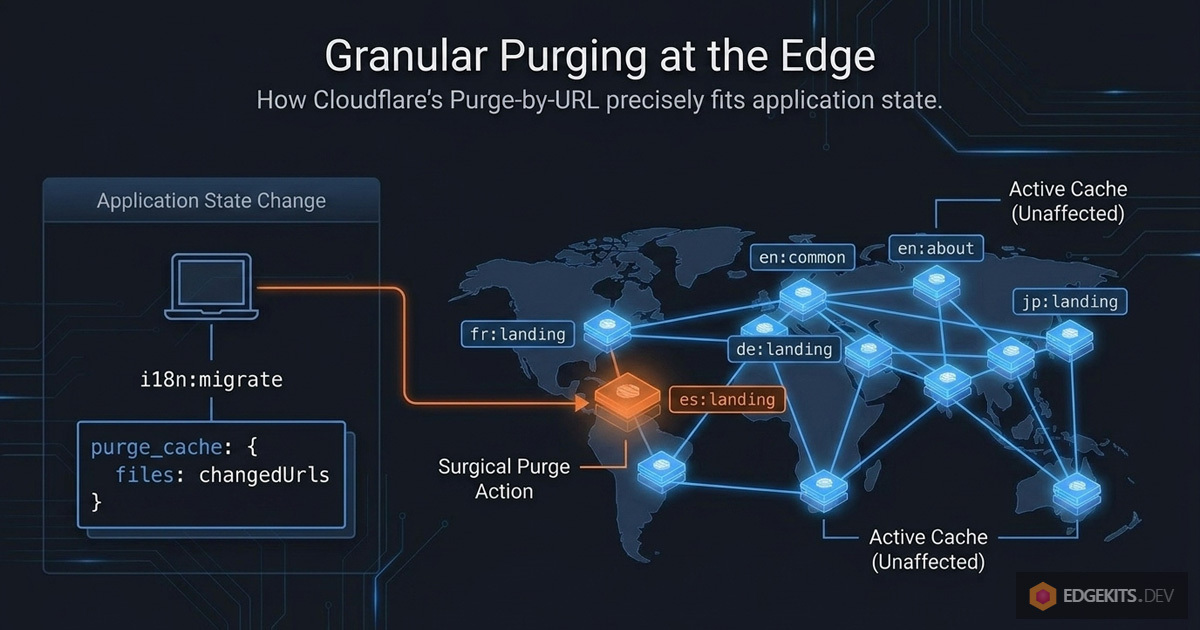
The fix: track which namespaces actually changed between migrations.
After every successful migration, compute a SHA hash of each locale:namespace JSON payload and store the results in .i18n-hashes.json. On the next run, recompute and diff:
const currentHashes: Record<string, string> = {}
for (const locale of locales) {
for (const ns of namespaces) {
currentHashes[`${locale}:${ns}`] = sha256(
JSON.stringify(translations[locale][ns])
)
}
}
const previousHashes = readHashFile() ?? {}
const changedKeys = Object.keys(currentHashes).filter(
(key) => currentHashes[key] !== previousHashes[key]
)
changedKeys is the exact list of pairs whose content differs from the last migration. Feed those into buildTranslationCacheUrl and you've got the precise list of URLs to purge. A single typo fix produces one or two API calls. Everything else stays warm.
One important detail: .i18n-hashes.json is gitignored local state. If the Purge API call fails - rate limit, expired token, network error - we deliberately don't update the hash file. On the next i18n:migrate run, the same namespaces still look "changed" and the retry happens automatically. Graceful recovery without manual intervention.
The full migration pipeline:
1. Read all locale JSON files
2. Compute current hashes per locale:namespace
3. Push translations to KV
4. Diff against previous hashes → changedKeys
5. If empty → skip purge
6. Build Purge URLs for changedKeys
7. Call Purge API in chunks of 30 (free tier rate limit)
8. On success → write updated hash file
9. On failure → log warning, skip hash update (retry next run)
After i18n:migrate completes successfully, the edge cache reflects the latest translations within seconds. No Worker redeploy. No version constant. No coupling.
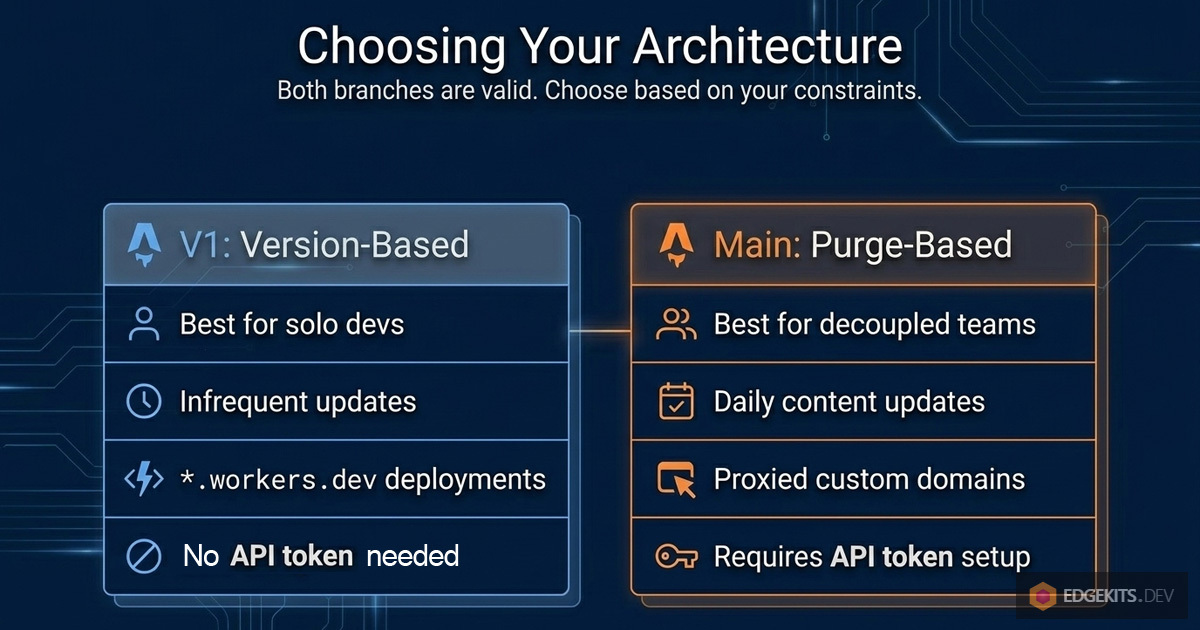
When to Use This vs. the Original Architecture
Both the content-hash approach (Part 1) and this explicit-purge approach are valid - they solve the same problem under different constraints.
Use the original content-hash architecture when:
- You don't want to manage an additional Cloudflare API token.
- Translations change rarely - once a month or only at release time.
- It's a solo project where "run two commands" isn't a real friction.
- You're on
*.workers.dev or a non-proxied domain.
Use the Purge API architecture when:
- Your domain is proxied through Cloudflare (orange cloud DNS).
- Translations change independently from code - content editors, translators, a CMS.
- You want a non-developer to deploy content changes without touching the codebase.
- Translation velocity matters: "seconds to propagate" vs. "wait for a deploy."
The key question is team composition and update frequency. If translations change once a month on release day, the redeploy requirement of the original architecture is nearly invisible - you're deploying anyway. If a marketing teammate needs to adjust hero copy weekly, the redeploy bottleneck becomes genuinely painful. Part 3 reduces that to one command.
For edgekits.dev, I knew I wanted a content workflow where non-developer updates were possible and translation iteration was cheap. The original architecture couldn't deliver that. For your project, the answer depends on which constraints actually dominate.
The Pattern Underneath
The refactor in this article was, underneath the implementation details, an exercise in putting each piece of state in the right layer.
Environment variables are for how the Worker is configured. They live with the Worker. They change when the Worker changes.
KV is for durable data the Worker reads. It lives independently of the Worker. It can change without a redeploy.
The Cache API is for transient acceleration. It's downstream of KV, populated by the Worker to save round-trips.
When TRANSLATIONS_VERSION lived in an env var, we were saying "this version is part of the Worker's identity" - and paying for that every time the version should change without the Worker itself changing. Putting versioning information in a build constant, then trying to update content independently of builds, was always going to produce friction. The state was in the wrong layer.
Static keys + explicit Purge API invalidation put each piece where it belongs: content in KV, cache entries downstream of KV, invalidation as an explicit out-of-band operation. Once the pieces sit in their right layers, the system composes cleanly and the coupling dissolves.
Get the Code
You don't have to build this from scratch. The entire architecture discussed today is available as an open-source starter kit: https://github.com/EdgeKits/astro-edgekits-core
The full deep-dive and complete implementation code for translations-keys.ts, fetcher.ts, and the migration script, production wrangler tail logs showing cache hit rates, and a detailed six-axis trade-off framework - is at edgekits.dev.