*Follow-up to *The Week I Stopped Coding
A month ago, I wrote about the moment I stopped coding and started orchestrating AI agents. That post was about the shift — the emotional and philosophical pivot from developer to director.
This post is about what happened after.
I built a system. Two physical machines on my home network, 14 containers, 35 concurrent AI coding sessions, and a 5-layer memory architecture that teaches agents not to repeat each other's mistakes. It scans my project management board every two minutes, picks up tickets, creates isolated git worktrees, spawns Claude Code sessions, writes code, creates pull requests, and updates ticket statuses — all without me touching a keyboard.
It processes 20-40 tickets overnight. I wake up to PRs.
I've Seen This Before
In 2015, I was drawing CI/CD pipeline diagrams on whiteboards at Kohl's. Build → Test → Publish → QA → Deploy → Stabilization → Release. The full continuous delivery loop, managed by hundreds of people across multiple teams — developers, QA engineers, DevOps, project managers, release coordinators.
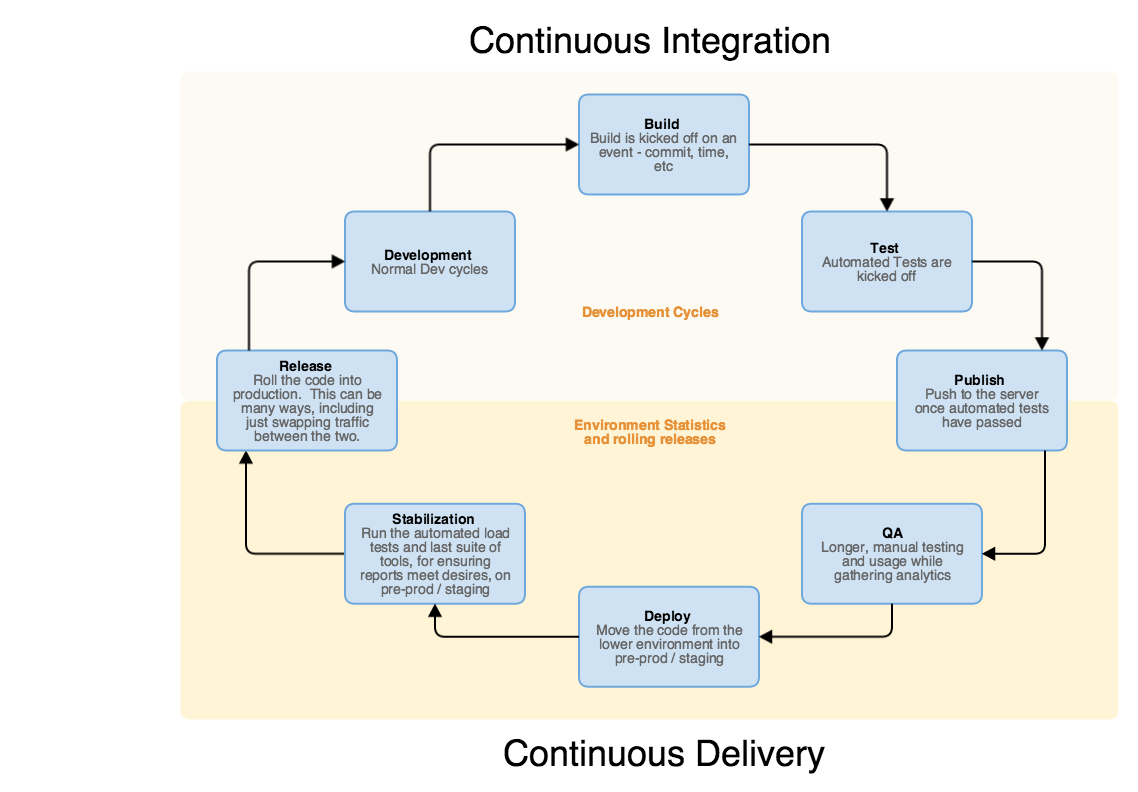
I look at that diagram now and I see my swarm's ticket lifecycle. The stages are identical. Linear scan is the ticket intake. The Claude Code session is the development cycle. Sub-agents run the build, test, and review gates. gh pr create is the publish step. Vercel auto-deploys on merge. Prometheus watches the stabilization metrics. The only difference is who's executing each stage.
In 2015, that loop required a branching strategy document that went through 11 revisions, a deployment runbook with IBM coordination steps, Chef cookbooks for node management, and a standing army of engineers. In 2026, it's one Node.js script and a vector database.
I'm not saying the people don't matter — they built the institutional knowledge that's now encoded in CLAUDE.md files and Qdrant collections. But the execution layer has fundamentally changed. The same pipeline I designed for human teams a decade ago now runs autonomously on two machines in my house.
The Hardware: Two Machines, One Network
No cloud compute for the swarm itself. Two machines on my home network — a Linux desktop and a Mac Studio I picked up for mobile builds.

Dragon (desktop) — Arch Linux, AMD ROCm GPU, 14 Podman containers. This is the primary orchestration node. It runs the director, the dashboard, Qdrant for vector search, Ollama for embeddings, and the full Prometheus/Grafana monitoring stack. 15 concurrent session slots.
Hive (Mac Studio) — The only machine with Xcode, iOS simulators, Android emulators, Fastlane, and Maestro for mobile QA. 20 concurrent session slots. Three macOS LaunchAgents handle its director, worker, and git-watcher processes.
They talk over SSH and a shared Qdrant instance. The desktop pushes build tasks to the hive's Qdrant — I use the vector database as a task queue because macOS LaunchAgents get EHOSTUNREACH when connecting back to the desktop IP. Flipping the direction solved it.
Total capacity: 35 concurrent AI coding sessions across 6 repositories.
The Three Layers
The architecture has three distinct layers, each operating independently.

Layer 2: Ops Runner. Infrastructure health. Zombie process detection every 15 minutes. TTL sweeps that mark tasks stuck over 30 minutes as failed. Metrics export to Prometheus — 43 metrics every 5 minutes. A React dashboard with 6 tabs that gives me visibility into what the swarm is doing. Without this layer, you don't know if the swarm is working or burning money.
Layer 3: Directors. This is the AI layer. Two directors — Dragon on the desktop handling backend and infrastructure (event-api, game-library, venues, monitoring, ops), Hive on the Mac Studio handling frontend and mobile (shindig, website). Each scans Linear every 2 minutes, routes tickets to the correct repo, creates git worktrees for isolation, and spawns Claude Code sessions.
The director is about 2,400 lines of Node.js. It's the single most important piece of the system — and in major need of refactoring. Now that I'm wrapping back around to making the ops swarm self-sufficient, it needs to follow its own linting and testing protocols. The irony of an autonomous coding system that doesn't enforce code quality on itself is not lost on me.
How a Ticket Becomes a PR

- Linear scan (every 120 seconds). The director queries for tickets in Agent Queue, QA Queue, QA Testing, or In Review. It checks attempt history — each ticket gets 3 shots before it's skipped.
- Ticket routing. Title prefix
[website] goes to the website repo. No prefix? Keyword matching. The detectRepo() function is blunt but effective:
function detectRepo(issue) {
const text = `${issue.title} ${issue.description || ''}`.toLowerCase();
// Check explicit repo names first
for (const repo of ['shindig', 'venues', 'event-api', 'game-library', 'website', 'monitoring']) {
if (text.includes(repo)) return repo;
}
// Mobile/app keywords → shindig
const shindigKeywords = ['maestro', 'e2e test', 'testflight', 'app store', 'play store',
'fastlane', 'ios', 'android', 'mobile', 'kotlin', 'swift', 'xcode', 'gradle',
'composable', 'jetpack', 'kmp', 'multiplatform', 'simulator', 'emulator',
'firebase auth', 'deep link', 'push notif', 'in-app purchase', 'storekit',
'billing', 'aab', 'ipa', 'bundle id', 'provisioning', 'signing key',
'app group', 'widget', 'crashlytics'];
for (const kw of shindigKeywords) {
if (text.includes(kw)) return 'shindig';
}
// Ops/infra keywords → ops
const opsKeywords = ['swarm', 'ops', 'ci/cd', 'pipeline', 'deploy', 'config',
'infrastructure', 'docker', 'podman', 'container', 'github action',
'orchestrat', 'director', 'dashboard', 'grafana', 'prometheus',
'script', 'automation', 'devops', 'agent', 'memory', 'qdrant',
'terraform', 'gcp', 'cloud run', 'fly.io', 'vercel'];
for (const kw of opsKeywords) {
if (text.includes(kw)) return 'ops';
}
return 'unknown'; // skip rather than routing to wrong repo
}
Fair warning: this is quick, dirty, get-it-running code. Not pretty. It works, it's being refactored, and I'm showing it because the pattern matters more than the polish.
This was the first pass. It's not sophisticated. It doesn't need to be. The title prefix catches 80% of tickets. The keyword fallback catches most of the rest. Unknown tickets get skipped — better to miss a ticket than route it to the wrong repo.
Since then, the routing has gone through a full arc. I added Linear labels, repo-specific tags, and more complex matching rules. It got more sophisticated — and harder to maintain. Now I'm simplifying back down: labels and tooling handle the routing upstream, so the director doesn't need 50 keywords to figure out where a ticket belongs. The lesson is the same one every system learns — the first simple version works, the complex version works harder, and the final version is simple again on purpose.
- Worktree creation.
git worktree add creates an isolated directory with its own branch: agent/fir-{ticketId}. Multiple tickets for the same repo can run in parallel without stepping on each other. This is essential — without worktree isolation, concurrent agents create merge conflicts on every commit.
- Session spawn. The director launches Claude Code with the ticket description, all comments, the repo's CLAUDE.md rules, and RAG context from prior agent learnings — all injected into the system prompt. Model starts at Sonnet. If it fails twice, it auto-escalates to Opus.
- Execution. The Claude Code session reads code, plans an approach, and spawns its own sub-agents — a researcher (Haiku), a coder (Sonnet), a tester (Haiku), and a reviewer (Haiku). Each sub-agent gets a fresh context window. No context pollution from the parent.
- PR creation. The session commits, pushes, creates a PR targeting the repo's base branch, and updates the Linear ticket status.
- Cleanup. Worktree removed. Pool slot freed. Next scan picks up more work.
The director also batches up to 4 tickets per repo into a single session, so the agent has broader context and can address related issues together. A typical ticket takes 5-60 minutes depending on complexity. The director fills available pool slots continuously. By morning, I have a stack of PRs to review.
Inside the Director: processTicket()
The heart of the system is processTicket(). This is the function that takes a ticket from the queue and turns it into a coding session. Here's what happens under the hood — model escalation, worktree creation, rate limit detection, and the failure classification that took me weeks to get right:
async function processTicket(ticket, config, state) {
let worktree;
try {
// Model escalation: after N failed attempts, upgrade to stronger model
const prev = state?.ticketsWorked?.[ticket.identifier];
const failedAttempts = prev ? prev.attempts : 0;
const threshold = config.escalationThreshold ?? ESCALATION_THRESHOLD;
const escalated = failedAttempts >= threshold && config.model !== config.escalationModel;
const ticketConfig = escalated
? { ...config, model: config.escalationModel }
: config;
if (escalated) {
log(`MODEL ESCALATION: ${ticket.identifier} failed ${failedAttempts}x ` +
`on ${config.model} → upgrading to ${config.escalationModel}`);
}
acquireLock(ticket.identifier, ticket.repo);
worktree = createWorktree(ticket.repo, ticket.identifier);
const result = await runClaudeSession(ticket, worktree.worktreePath, worktree, ticketConfig);
if (!result.success) {
const tail = result.output.slice(-300);
// Detect rate limit OR auth failure errors
const isRateLimit = RATE_LIMIT_PATTERNS.some(p => p.test(tail));
const isAuthFailure = AUTH_FAILURE_PATTERNS.some(p => p.test(tail));
const isFastFail = result.duration_ms < FAST_FAIL_THRESHOLD_MS && !result.timedOut;
// Fast failures (< 10s) are never real work — don't burn attempts
if (isFastFail) {
result.rateLimited = true;
log(`FAST FAIL: ${ticket.identifier} died in ` +
`${Math.round(result.duration_ms / 1000)}s — not counting as attempt`);
}
if (isRateLimit || isAuthFailure) {
if (!rateLimitState.detected) {
rateLimitState.detected = true;
// Parse reset time, default to 4am Central
const resetMatch = result.output.match(
/resets?\s+(\d+)\s*(am|pm)\s*\(([^)]+)\)/i
);
// ... calculate sleep duration, auto-pause director
notifySlack(`:warning: Director hit rate limit. Auto-pausing until reset.`);
}
}
}
return { ticketId: ticket.identifier, success: result.success, ... };
} finally {
releaseLock(ticket.identifier);
cleanupWorktree(worktree);
}
}
Same caveat as above — this is working code, not clean code. The director script is 2,400 lines of Node.js that grew organically as failures taught me what it needed to handle. Refactoring it is on the roadmap.
The escalation logic is simple: attempts 1-2 run on Sonnet. Attempt 3 auto-upgrades to Opus. The rate limit detection is what took the most iteration — the system had to learn the difference between "this ticket is hard" and "the infrastructure is down." That distinction saved me from permanently skipping dozens of viable tickets.
How Do You Solve AI Agent Memory Loss?
AI agents are amnesiac by default. When I started, a Claude Code session got 200K tokens of context. Now Opus 4.6 has a 1M token window. Bigger helps — but the fundamental problem is the same. The moment the session ends, everything it learned disappears. The next agent assigned a similar ticket starts from zero and makes the same mistakes.
This is the fundamental problem of autonomous AI coding at scale. I solved it with 5 layers of memory, each serving a different persistence scope.

Layer 2: CLAUDE.md files. Checked into git at each repo root. Every agent session in a repo automatically loads these rules — branch patterns, build commands, quality standards, things the agent must never do. This is institutional knowledge encoded as configuration.
Layer 3: File memory. Claude Code's auto-memory system at ~/.claude/projects/. Over 20 topic files covering build pipelines, secret management, deployment procedures, lessons learned. Survives across sessions on the local machine.
Layer 4: Vector memory. Qdrant stores nearly 16,000 knowledge points and all agent outcomes. Before starting work, agents query for relevant prior learnings using semantic search. After completing work, they record what happened — success or failure, with context. This is how the swarm learns. A failed Gradle build gets recorded. The next agent searching "shindig android build" finds it and doesn't repeat the same mistake.
Layer 5: Linear tickets. The human-agent interface. I embed decisions directly in ticket descriptions and comments. Agents read both before acting. This is the only layer where I actively participate in the memory system.
The key insight: agents query Qdrant before starting work and record outcomes after finishing. A memory-agent container consolidates learnings every 6 hours. The swarm genuinely learns from its own history.
The Failures
This is the part that matters. Anyone can describe an architecture. The real story is in how it broke.
124 Pull Requests Overnight
I woke up to 124 open PRs on one repo. About 90 were duplicates — the same tickets processed over and over because the director never checked whether a PR already existed. It would scan Linear, find tickets in Agent Queue, spawn sessions, create PRs — but never move tickets out of Agent Queue. Next scan cycle: same ticket, new branch, new PR.
While I was closing duplicates, the hive director kept creating new ones. 7 more appeared during cleanup.
The fix: Dedup guard. Check for existing PRs before creating new ones. Move tickets to In Progress when work starts, In Review when the PR is created. Deterministic branch naming — no random suffixes.
The lesson: If your agent loop doesn't track what it already did, it will do everything twice.
Every Session Ran on Opus
I noticed rate limits being hit in hours instead of lasting all day. The director script never passed a --model flag. Claude Code defaults to Opus — the most expensive model. 747+ sessions ran on Opus before I caught it.
One missing CLI flag. Token consumption was 3-5x what it needed to be. A $15/day operation became $65/day.
The fix: Added --model sonnet as default. Model escalation: attempts 1-2 use Sonnet, attempt 3 auto-escalates to Opus. Immediate 3-5x cost reduction.
The lesson: Defaults matter enormously at scale. A single missing flag multiplied by 1,000 sessions turned a cost-effective operation into a budget-burner.
46 out of 46 Sessions Failed in One Cycle
The director launched 46 sessions. Every single one died within 1-20 seconds with "You've hit your limit." The director treated these as normal failures, incremented attempt counters, and after 3 "failures" permanently skipped each ticket.
By morning, 37 tickets were stuck in limbo and dozens were marked as "max attempts exceeded" — even though the failures had nothing to do with the tickets themselves.
The fix: Rate limit pattern matching. Auth failure detection. Fast-fail threshold — sessions dying in under 10 seconds don't count as real attempts. If >80% of a cycle's sessions fail fast, auto-pause the director and sleep until the rate limit resets.
The lesson: Your orchestrator must distinguish between "the task failed" and "the infrastructure failed." Burning ticket attempts on rate limits is like marking a restaurant order as "rejected by customer" because the kitchen caught fire.
The Agent That Sent Me on a Wild Goose Chase
A Haiku-model agent was assigned an Apple Sign-In bug. After a brief code scan, it confidently told me: "The Firebase Console needs com.firefly.shindig.dev added as an authorized domain."
I spent 20 minutes checking the Firebase Console. It was already correct. The .dev bundle ID doesn't even exist — the app uses com.firefly.shindig.ios.
The real problem was three code bugs the agent never found.
The fix: Verification protocol. Agents can't tell humans to change external config without file-and-line code evidence. Memory files take precedence — if memory says it's configured and working, the agent needs strong evidence before claiming otherwise. Config-level claims get escalated to Opus for verification.
The lesson: An agent that confidently sends you on a wild goose chase is worse than one that says "I don't know." Cheaper models need guardrails that prevent authoritative claims about systems they can't inspect.
OAuth in Containers: Three Login Attempts Destroyed
Claude Code authenticates via OAuth. Tokens expire and refresh automatically. I tried three approaches to get auth working in Podman containers:
- Run
claude login inside the container. Works until restart — credentials wiped.
- Base64-encode credentials as an env var. The entrypoint script always decodes on startup, overwriting any token refresh.
- Copy host credentials at build time. Stale by the time the container runs.
The fix: Bind-mount the host credentials file directly into the container:
volumes:
- ${HOME}/.claude/.credentials.json:/home/swarm/.claude/.credentials.json:rw
Login once on the host, container stays authenticated across restarts, rebuilds, and token rotations. Set the env var to empty string so the entrypoint skips injection.
The lesson: Live auth tokens must be shared, not copied. Any approach that snapshots a token creates a stale copy.
Five Zombie Detectors, All Broken
After the 124-PR incident, I discovered agent processes that finished work but never exited. They consumed memory and held file locks, preventing new sessions.
I had five separate zombie detection mechanisms. Not one caught the problem.
The bash script only checked for duplicates, not resource thresholds. The task-level checker only looked at output file freshness. The cleanup script explicitly skipped daemon processes. The ops runner only checked Qdrant task state. The container-based detector couldn't see outside its own namespace.
The fix: One detection mechanism that actually works end-to-end. Process-level zombie detection in the ops runner. Session timeout as a catch-all.
The lesson: Five bad detectors are not better than one good one. Each was built for a specific variant of the problem but had blind spots. The result was false confidence.
The Numbers
Over 7 weeks of operation:

| Metric | Value |
|---|
| Total agent runs | 6,500+ |
| Repos covered | 6 |
| Peak day (March 5) |