Most engineers meet Apache Iceberg as a one-line answer: "it's the thing that
gives you ACID transactions and time travel on object storage." That's true, and
it's also where most people stop. But Iceberg has a version dial baked into every
table - a single integer called format-version, currently 1 through 4 - and
each turn of that dial is a chapter in a single, surprisingly coherent story.
It's a story about pushing transactional behavior down through layers. v1 made a
table atomic on top of immutable files, but it could only append and overwrite
whole files. v2 pushed correctness down to the row. v3 pushed identity down to
the row, so a row keeps the same id across compactions. v4 turned around and
refactored the metadata itself so it can scale and move without rewrites.
To follow that arc you need the one mental model the rest of this post hangs
on. So we start there, then walk the four versions in order, keeping the parts
that actually matter for understanding what's on disk.
The primer: an Iceberg table is a tree of files, not a folder
The instinct everyone brings from Hive is that a table is a directory: point at
a path, list the files under it, that's your table. Iceberg breaks that instinct
on purpose. An Iceberg table is not a directory of data files. It is a
tree of immutable metadata files rooted at a single pointer held in a
catalog.
Every commit appends new files to that tree and atomically moves the pointer.
Nothing is ever mutated in place. That single design choice - immutable files,
one movable pointer - is what makes everything else possible.
The tree has five layers:
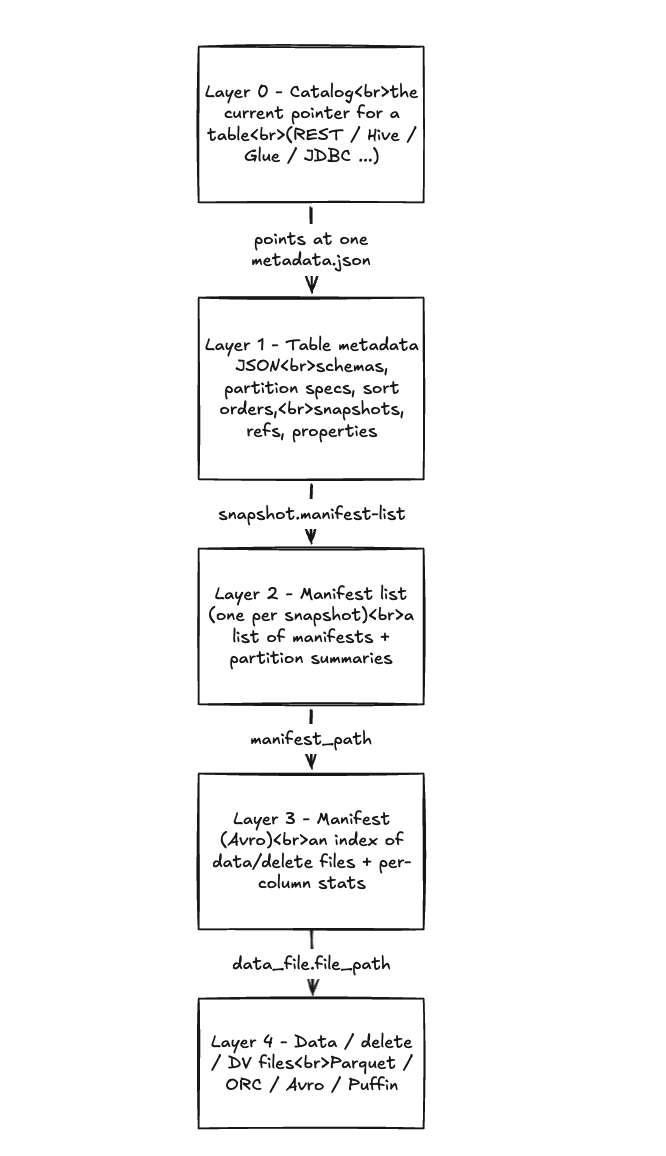
Read it top to bottom and you have the whole format:
- Layer 0 - the catalog. It holds one fact per table: "the current pointer
for prod.db.sales is this metadata file." The catalog is the only mutable
thing in the entire system, and it lives outside the format spec (REST
catalog, Hive Metastore, Glue, JDBC, and so on).
- Layer 1 - the table metadata JSON. A new one is written on every commit.
It holds the schemas, partition specs, sort orders, table properties, the list
of snapshots, and named references. This is the file the catalog points at.
- Layer 2 - the manifest list. One per snapshot. An Avro file listing the
manifests that make up that snapshot, each row carrying a partition summary so a
scan can skip whole manifests it doesn't need.
- Layer 3 - the manifests. Avro files, each an index over a set of data or
delete files, with per-column statistics for each file.
- Layer 4 - the data. The actual Parquet/ORC/Avro files, plus delete files
and deletion-vector blobs.
Why build a table this way? Two reasons, and they're the whole pitch:
- Atomic commits without coordination. Because everything below the catalog
is content-addressed by path and never mutated, readers and writers can build
files independently with no locking. The only contended operation in the
entire system is the catalog pointer swap. One compare-and-set, and the commit
is either visible or it isn't.
- Cheap reads. A scan loads the manifest list (roughly 100 KB even for a
huge table), prunes manifests by partition, and only then opens any data file.
You never list a directory; you walk an index.
On disk, a table looks roughly like this:
s3://warehouse/db/sales/ <- table location
metadata/
00001-....metadata.json <- Layer 1: root JSON, one per commit
00002-....metadata.json
00042-....metadata.json <- currently pointed at by the catalog
snap-....avro <- Layer 2: a manifest list per snapshot
8ef6-....avro <- Layer 3: manifests
9b21-....avro
stats-....puffin <- optional: table stats (NDV sketches)
data/
year=2025/month=06/00000-0-....parquet <- Layer 4: data
year=2025/month=06/00001-0-....parquet
dv-....puffin <- Layer 4: deletion vectors
Hold that picture. Every version below is a change to one or more of these five
layers, and the format-version integer in Layer 1 is what tells a reader which
rules apply. A reader that supports up to version N will refuse to open a table
whose format-version is higher than N rather than silently misread it.
Now the four chapters.
v1: a table that's atomic, but only at the file
v1 is the foundation, and it nails the hard part: snapshot isolation and atomic
commits on immutable files. A v1 table already has schemas, partition specs,
snapshots, and time travel. If all you ever do is append data and occasionally
overwrite whole files, v1 is a complete, correct table format.
Its limits are exactly the things the later versions go after.
It can't delete or update a single row. The smallest unit v1 can change is a
file. Want to delete one row? Rewrite the entire file without it, then swap the
file in a new snapshot. This is copy-on-write, and on a wide table it means
rewriting gigabytes to remove a handful of rows.
Its metadata carries a few quirks that v2 had to clean up:
- The schema and partition spec were stored as singular fields - one schema,
one spec - rather than a list of historical ones. A v1 metadata file has a
schema and a partition-spec; both are deprecated from v2 onward in favor of
schemas[] and partition-specs[].
- Partition field IDs were not tracked explicitly. Implementations just
assigned them sequentially starting at 1000. That caused real ambiguity when
the same logical field got a different transform across specs - there was no
stable identity to tie them together.
- A snapshot could embed its manifests inline as a
manifests: [path, ...]
list instead of pointing at a separate manifest-list file. Convenient, but it
meant the per-snapshot bookkeeping that later inheritance rules depend on had
nowhere to live.
- A few
data_file fields existed that nobody needed: block_size_in_bytes,
file_ordinal, sort_columns. All removed in v2.
None of this makes v1 wrong. It makes v1 append-shaped. The entire push of v2
is to make the table mutable at the row, and to add the bookkeeping that makes
that safe.
v2: correctness pushed down to the row
v2 is the version most production tables ran on for years, because it's the one
that turns Iceberg from an append log into a real transactional table. Three big
ideas arrive together: row-level deletes, sequence numbers, and named
references.
Row-level deletes: merge-on-read
Instead of rewriting a file to remove rows, v2 lets you write a small delete
file that says "these rows in that data file are gone." The reader applies
deletes on the fly at scan time. This is merge-on-read, and it comes in two
flavors:
- Position deletes - a list of
(file_path, position) tuples: "row 42 and
row 1007 of this file are deleted." Precise, cheap to write, used by DELETE
and MERGE.
- Equality deletes - a predicate on column values: "any row where
id = 12345 is deleted." These don't need to know where the row lives, which
makes them ideal for streaming upserts where you delete-then-insert without
reading the old file first.
To make this work, the format needed a way to say whether a file holds data or
deletes, and a way to order deletes against data. Both arrived in v2.
The content discriminator and sequence numbers
A v2 manifest, and each file it lists, now carries a content field. On the
manifest list it's 0 = data or 1 = deletes; a single manifest holds either
data files or delete files, never both, so scan planning can load all the
delete manifests first. On the data file itself, content is 0 = DATA,
1 = POSITION_DELETES, 2 = EQUALITY_DELETES.
The ordering problem is subtler. If a delete file says "delete id = 12345,"
which inserts of that id does it kill - the ones before it, or also the ones
after? v2 answers this with a monotonic sequence number assigned at commit
time and threaded through every layer:
- The table metadata tracks
last-sequence-number, bumped on each commit.
- Each snapshot records its
sequence-number.
- The manifest list records each manifest's
sequence_number and a
min_sequence_number (the smallest data sequence number among live files in
it).
- Each manifest entry carries the file's
sequence_number.
The rule that falls out: an equality delete applies to a data file only when
the delete's sequence number is greater than the file's (and they share a
partition). A position delete applies at equal-or-greater sequence. That's how
"delete then insert" does the right thing - the new insert has a higher sequence
number than the delete, so it survives.
Inheritance: why this is cheap
Here's the piece that surprises people. A manifest entry can leave its
snapshot_id, sequence_number, and file_sequence_number null in the
file, and the reader fills them in from the manifest list. Why bother? Because
it lets the same manifest file be reused across optimistic-retry attempts. When
a commit loses the compare-and-set race and has to retry with a new sequence
number, only the small manifest list needs rewriting - the manifests and data
files it points at are untouched.
v2 adds a refs map to the table metadata - named branches and tags pointing at
snapshots:
"refs": {
"main": { "snapshot-id": 8392648, "type": "branch" },
"audit": { "snapshot-id": 8000000, "type": "branch",
"min-snapshots-to-keep": 10, "max-snapshot-age-ms": 604800000 },
"prod_release":{ "snapshot-id": 7281001, "type": "tag",
"max-ref-age-ms": 2592000000 }
}
main always exists; if refs is empty it implicitly points at
current-snapshot-id. Branches let you stage and validate writes off to the side
(write-audit-publish); tags pin a snapshot so expiration won't garbage-collect
it. Branches carry their own retention floor (min-snapshots-to-keep,
max-snapshot-age-ms); tags and non-main branches carry max-ref-age-ms. main
never expires.
v2 also formalized a lot of Layer 1. These fields became required:
last-sequence-number, current-schema-id, schemas, default-spec-id,
partition-specs, last-partition-id, default-sort-order-id, sort-orders,
and table-uuid (a stable identity generated at create time, used as a
refresh-time integrity check). The singular schema and partition-spec are
deprecated, the inline snapshot manifests list is gone, and partition field IDs
are now explicit and unique across all specs - fixing the v1 ambiguity.
One nice compatibility property: a v1 file reads cleanly as v2. A missing
sequence_number is read as 0, and a missing content is read as 0 (data). So
upgrading is a metadata-only operation; nothing has to be rewritten on day one.
By the end of v2, Iceberg is a full transactional table: insert, delete, update,
upsert, branch, tag, time-travel. So what's left for v3?
v3: identity, efficient deletes, and richer data
If v2 made the table transactional, v3 makes the row a first-class citizen.
It adds three things that don't fit neatly into v2's model: a stable identity for
every row, a far more efficient delete mechanism, and a richer type and security
surface.
Row lineage: every row gets a stable id
This is the headline feature, and it's genuinely clever because it touches three
layers at once without storing an id per row anywhere. v3 mandates that every row
has a stable _row_id that survives compaction - so you can track a row across
rewrites, build change feeds, and reason about lineage. It works by seeding,
not storing:
| Layer | Field | Set when | Used for |
|---|
| 1 (table metadata) | next-row-id | bumped per commit | seeds the next snapshot's first row id |
| 2 (snapshot) | first-row-id, added-rows | at commit | starting _row_id for the manifest list |
| 2 (manifest list) | first_row_id per manifest | at commit | starting _row_id for files in that manifest |
| 3 (manifest entry) | data_file.first_row_id | at commit | starting _row_id for rows in that file |
| 4 (data file) | reserved fields _row_id, _last_updated_sequence_number | inherited at read | stable identity across compactions |
The reader computes a row's id with one formula:
_row_id = data_file.first_row_id + row_position_in_file
No per-row storage; the id is derived from where the row sits. If first_row_id
is null - say a v2-era file in a table that was upgraded to v3 - then _row_id
reads as null for those rows, which is exactly the honest answer. Equality
deletes deliberately break lineage: an equality-delete update never reads the old
row, so the replacement gets a fresh _row_id rather than inheriting one it
can't prove.
Deletion vectors: position deletes, done right
Position delete files worked, but they had a scaling problem: lots of tiny
delete files, each needing to be opened and merged. v3 replaces them with
deletion vectors (DVs) - a single compressed bitmap per data file, stored as
a blob inside a Puffin file. One bitmap, one referenced data file, looked up by
byte offset.
The manifest entry for a DV reuses the position-delete content code but adds
three fields:
manifest_entry {
status = 1
data_file {
content = 1 // shares position-delete code
file_path = "s3://warehouse/db/sales/data/dv-....puffin"
file_format = "puffin"
partition = { country: "IN", ts_day: 2025-06-15 } // same partition as target
record_count = 3 // number of deleted positions
referenced_data_file = "s3://.../00000-abc.parquet" // v3 NEW: which data file this DV covers
content_offset = 4 // v3 NEW: byte offset of the blob in the Puffin file
content_size_in_bytes= 23 // v3 NEW: blob length
}
}
referenced_data_file, content_offset, and content_size_in_bytes are the new
fields that let the reader jump straight to one bitmap. Position delete files are
deprecated in v3: writers can't create new ones, and existing ones get merged
into DVs over time. The result is one delete artifact per data file instead of a
pile of small files.
New types and column defaults
v3 broadens what a column can hold. New primitive types: variant (semi-
structured), geometry and geography (spatial), unknown (a column whose type
isn't known yet), and nanosecond timestamps timestamp_ns / timestamptz_ns.
It also adds column defaults, which finally make adding a non-null column
sane:
{
"id": 5, "name": "country", "type": "string", "required": false,
"initial-default": "IN", // value for rows in files written before this column existed
"write-default": "IN" // value to fill when a writer omits the column
}
initial-default is the value that existing rows get for a freshly added
column, with no file rewrite - the reader synthesizes it. write-default is what
new writes use when the column is omitted. Together they make schema evolution a
metadata change instead of a backfill.
The type-promotion rules that keep schema evolution safe also expand in v3:
| From | v1 / v2 promotion | v3+ adds |
|---|
unknown | - | promotable to any type |
int | long | long |
date | - | timestamp, timestamp_ns (not the tz variants) |
float | double | double |
decimal(P, S) | decimal(P', S) with P' > P | same |
v3 adds source-ids (plural) on partition fields, so a transform can take more
than one source column. Single-argument transforms still write the old
source-id. The full set of allowed transforms is identity, bucket[N],
truncate[W], year, month, day, hour, and void. And a forward-
compatibility rule lands: v3 readers must tolerate an unknown transform and
simply skip filter pushdown on it, rather than refusing to read. (v1/v2 only
should.) Writers, of course, still can't commit a transform they don't
understand.
Encryption arrives
v3 adds table-level encryption with a three-place key model:
"encryption-keys": [
{ "key-id": "k1",
"encrypted-key-metadata": "BASE64...", // KMS-wrapped data encryption key
"encrypted-by-id": "kms-master-2025" } // the logical key-encryption-key id
]
- The table JSON holds
encryption-keys[] - data encryption keys (DEKs) each
wrapped by a KMS-resident key-encryption-key (KEK).
- Each snapshot carries a
key-id naming which DEK protects that snapshot's
manifest-list key metadata.
- Each file can carry per-file
key_metadata (this field already existed in
v1/v2 on data files, but without a central registry).
The DEK-to-KEK chain is opaque to the format; implementations plug into AWS KMS,
GCP KMS, Vault, and so on via the wrapped bytes.
By the end of v3, a row has an identity, deletes are a single bitmap, columns can
default and hold variant or spatial data, and the table can be encrypted. The
user-visible feature set is essentially complete. Which is why v4 looks
different from everything before it.
v4: the refactor for scale and portability
v4 introduces no new user-visible types and no new delete mechanisms. It is a
metadata refactor aimed at three things: performance, portability, and richer
per-file statistics. The changes are quieter, but two of them matter a lot in
production.
Relative paths: move a table without rewriting it
This is the biggest invisible change in the whole format. In v1 through v3,
every path stored inside metadata - file_path, manifest_path, the manifest
list, metadata-file, statistics paths - had to be absolute, complete with a
URI scheme like s3:// or hdfs://. That meant the moment you wanted to move a
table to a different bucket, every one of those absolute paths was wrong, and you
had to rewrite the entire metadata tree to fix them.
v4 allows paths to be relative to the table location. The resolution rule is
simple:
| Format | Table location | Stored path | Resolves to |
|---|
| v4 | s3://bucket/db/table | data/00000.parquet | s3://bucket/db/table/data/00000.parquet |
| v4 | s3://bucket/db/table | hdfs://wh/... | hdfs://wh/... (absolute, used as-is) |
| v3 and earlier | s3://bucket/db/table | s3://bucket/db/table/data/00000.parquet | unchanged |
If a stored path has a URI scheme, it's absolute and used as-is. If it doesn't,
the reader resolves it as table_location + "/" + path. The writer rule:
default to relative for files under the table location, use absolute for files
outside it (say, a backfill from another bucket). Because location is now what
ties relative paths together, location in the table metadata JSON becomes
optional - the catalog can supply it.
The operational payoff is the headline: moving a table from
s3://bucket-a/db/sales/ to s3://bucket-b/db/sales/ needs only a catalog
pointer update and, optionally, a new metadata.json with the new location. No
manifest list, no manifest, no data file gets rewritten. Pre-v4 the same move
required a full metadata rewrite.
Typed content_stats: five maps become one struct
In v3 and earlier, per-column statistics on a data file were five parallel
maps keyed by field id: value_counts, null_value_counts,
nan_value_counts, lower_bounds, upper_bounds (plus the on-disk
column_sizes). Five maps to keep in sync, all loosely typed (bounds were raw
binary-encoded bytes).
v4 replaces them with one typed struct, content_stats, whose layout is
generated from the table schema itself. Each column reserves a block of ids and
gets a typed sub-struct:
146: optional struct content_stats {
10_400: optional struct id (default null) { // stats for table field 2 (int)
10_401: optional int lower_bound;
10_402: optional int upper_bound;
10_403: optional boolean tight_bounds;
10_404: optional long value_count;
}
10_600: optional struct data (default null) { // stats for table field 3 (string)
10_601: optional string lower_bound;
10_602: optional string upper_bound;
10_603: optional boolean tight_bounds; // v4 NEW: exact vs truncated min/max
10_604: optional long value_count;
10_605: optional long null_value_count;
10_607: optional int avg_value_size_in_bytes; // v4 NEW: variable-length sizing
}
}
The id assignment is mechanical - each column reserves 200 ids - and two genuinely
new pieces of information appear: tight_bounds, a flag saying whether the
min/max are exact or truncated (truncated bounds still prune, but you have to scan
to confirm a match), and avg_value_size_in_bytes for variable-length columns,
which helps the planner estimate read cost. Spatial columns use typed
geo_lower / geo_upper structs instead of opaque WKB bytes.
The reassuring part: v3 and v4 statistics are equivalent. A missing map key in
v3 is the same as a missing-or-null sub-struct in v4. Nothing is lost in the
translation; it's the same information, typed and consolidated.
The file-system catalog is gone
v1 through v3 allowed a "file-system table": sequential metadata filenames
(v1.metadata.json, v2.metadata.json, ...) where a commit was an atomic file
rename. That only ever worked safely on HDFS, because object stores like S3
don't offer atomic rename. v4 removes it entirely. Every v4 table uses a real
catalog (the metastore model), where a commit is a compare-and-set on the catalog
pointer. This closes a long-standing source of silent corruption on object
storage.
That's the whole of v4: relative paths, optional location, typed
content_stats with tight_bounds and average value size, and the death of the
file-system catalog. A refactor, not a feature release - and exactly the kind of
change a format makes once its feature surface has settled.
How the layers earn their keep: scan planning
The reason all this structure exists is to make a scan cheap, so it's worth
watching a query actually use it. Given the current snapshot, a scan does
three-level pruning without ever needing a separate planner index:
- Open the manifest list. One read, roughly 100 KB.
- Layer-2 pruning. Drop any manifest whose partition summary can't match the
query predicate. Whole manifests skipped without opening them.
- Open the surviving delete manifests first, then the data manifests. Delete
manifests come first so the reader knows which deletes are in play before it
decides what to emit.
- Layer-3 pruning. For each data file, check its
lower_bounds /
upper_bounds; if they rule the file out, skip it. Otherwise emit it as a scan
task.
- Pair each scan task with the deletes that apply, using the sequence-number
rules from v2:
- a deletion vector applies when its
referenced_data_file matches and its
sequence is greater-or-equal, in the same partition;
- a position delete applies by the same rule, but only when no DV is present;
- an equality delete applies when its sequence is strictly greater than the
data file's, in the same partition (or globally if unpartitioned).
Manifest list, then manifest, then file. Three reads narrow a petabyte table to
the handful of files a query actually needs. That funnel is the entire reason the
tree-of-files design beats a directory listing.
Reading across versions
A practical note that saves real debugging time: the format is designed so older
files read correctly under newer rules.
- v1 read as v2: a missing
sequence_number is 0; a missing content is 0
(data). Upgrading v1 to v2 is metadata-only.
- v2 read as v3: files without
first_row_id simply report _row_id as null;
position delete files keep working but can't be created anew.
- v3 read as v4: a missing stats map key equals a null typed sub-struct; absolute
paths keep working unchanged alongside new relative ones.
And the one hard rule in the other direction: a reader refuses to open a table
whose format-version is higher than the reader supports. The version integer is
a contract, not a hint.
The whole format on one page
Here is the entire metadata surface, top to bottom, with the version each piece
arrived in:
catalog -> metadata.json
|-- table level: format-version, schemas[], partition-specs[], sort-orders[],
| properties{}, last-*-id, last-sequence-number, encryption-keys[] (v3+)
|-- refs{} -> main / branches / tags -> snapshot-id (v2+)
|-- snapshots[] (whole history; expired entries pruned)
|-- one snapshot:
snapshot-id, parent-snapshot-id, sequence-number, summary{op,...},
first-row-id + added-rows (v3+), key-id (v3+)
|-- manifest list (Avro): [ manifest_file x N ]
manifest_file: path, len, spec-id, content (data|deletes), (v2+)
seq#, min_seq#, counts, partitions[],
first_row_id (v3+)
|-- manifest (Avro): header{schema, spec, content} + [ entry x N ]
entry: status, snapshot_id, seq#, file_seq#,
data_file {
content, file_path, format, partition,
record_count, size, sort_order_id,
metrics maps (v1-v3) -- OR -- content_stats struct (v4),
equality_ids (v2+),
referenced_data_file / content_offset / size (v3+),
first_row_id (v3+), key_metadata
}
|-- data file / delete file / Puffin DV blob
And the version-by-version cheat sheet:
| v1 | v2 | v3 | v4 |
|---|
| Core model | atomic snapshots on immutable files | + row-level deletes, sequence numbers | + stable row identity | metadata refactor only |
| Deletes | rewrite whole file (copy-on-write) | position + equality delete files | deletion vectors (position deletes deprecated) | unchanged |
| Schema/spec | singular schema / partition-spec | lists, explicit partition field ids | column defaults, new types, source-ids | unchanged |
| References | - | refs: branches + tags | unchanged | unchanged |
| Row lineage | - | - | next-row-id / first-row-id / _row_id | unchanged |
| Types | base | + sort orders | variant, geometry, geography, unknown, ns timestamps | unchanged |
| Encryption | per-file key metadata only | per-file key metadata only | encryption-keys, snapshot key-id | unchanged |
| Statistics | metrics maps | metrics maps | metrics maps | typed content_stats + tight_bounds |
| Paths | absolute only | absolute only | absolute only | relative or absolute; location optional |
| Catalog | file-system or metastore | file-system or metastore | file-system or metastore | metastore only |
Every commit appends a new metadata.json plus new manifest-list, manifest, and
data files. The old tree stays reachable through the metadata log for rollback
and time travel, until snapshot expiration garbage-collects it. Nothing is ever
mutated; the whole format is an append-only tree with one movable pointer at the
root.
The throughline
Read the four versions back to back and the arc is clean. v1 made a table
atomic on immutable files. v2 pushed correctness down to the row with deletes
and sequence numbers, and added branches. v3 pushed identity down to the row,
made deletes a single bitmap, and broadened types and security. v4 turned inward
and refactored the metadata so it can move and scale without rewrites.
It's the same instinct applied at finer and finer grain: make the unit of change smaller, and make the metadata that tracks it cheaper. That's why a format that started as an append-only snapshot log can now back a streaming upsert table with row-level lineage across petabytes - without ever giving up the one property it started with, the single atomic pointer swap.
If you want to build this understanding from the ground up - why data lakes broke,how snapshots and manifests really work, and the hands-on mechanics of deletes,branches, and compaction - that's the
Iceberg Foundations track,
part of the broader open table formats
curriculum. The format rewards reading it as a story, because that's how it was written.