Over 36 hours we ran four DPO training iterations against Qwen2.5-Coder-7B-Instruct, trying to push HumanEval pass@1 above the base model's 87.20%. The first three iterations failed in different ways (-9.15pp, -1.22pp, two NO-GO calls). The fourth recovered to +0.61pp.
Each failure revealed a different class of bug in our chosen-sample generation pipeline — bugs the existing certification gates were not catching. This post walks through the four iterations and what we ended up building to fix them.
We're sharing this because the same gate-blindness probably affects most teams running DPO on autopilot-generated data. The bugs we found were not exotic; the gates that missed them were not naive.
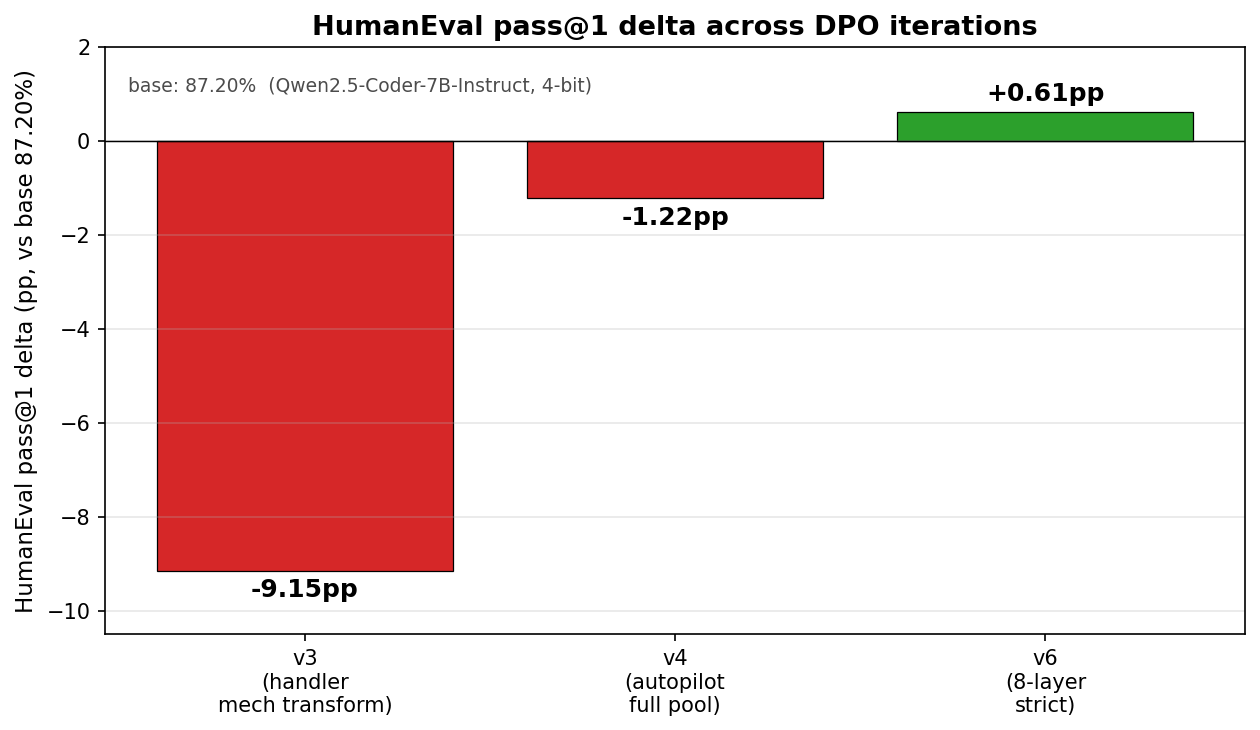 Δpp vs base (Qwen2.5-Coder-7B-Instruct, 4-bit, 87.20% pass@1). Each bar represents one full DPO training run.
Δpp vs base (Qwen2.5-Coder-7B-Instruct, 4-bit, 87.20% pass@1). Each bar represents one full DPO training run.
The setup
We have a pipeline that generates Python code samples paired with synthetic pytest tracebacks, then runs each sample through a quality gate that checks four things in sequence:
- Invariant test — domain-specific contract (e.g.
mcmc_sample(...) must return a list of length n_samples)
- Differential test — numerical comparison against a reference implementation
- Property test — Hypothesis-based property checking
- Fuzz test — fixed adversarial-input catalog
If all four pass, the row gets certified=1 and becomes eligible as a DPO chosen sample. We pair it with broken implementations from the same domain (rejected samples) and feed the pairs to Unsloth to fine-tune Qwen2.5-Coder-7B-Instruct via LoRA.
That's the pipeline. The first three iterations broke it in different places.
Our first iteration built chosen samples by transforming broken code:
NameError → prepend the missing import based on a known-import mapModuleNotFoundError → wrap the import in try/except ImportErrorAssertionError → replace assert X == Y with pass
We trained on 2,000 such pairs (96% NameError, ~3% AssertionError, the rest ImportError).
HumanEval: 87.20% → 78.05%. Δ = -9.15pp.
The failure category breakdown showed exactly where it went wrong:
| Failure category | Base | iter v3 | Δ |
|---|
| ASSERTION_FAIL | 18 | 28 | +10 |
| OTHER_RUNTIME | 1 | 5 | +4 |
| SYNTAX_ERROR | 0 | 2 | +2 |
| TOTAL FAIL | 21 | 36 | +15 |
ASSERTION_FAIL accounted for 67% of the regression alone. The model had learned the wrong lesson from the AssertionError handler: "if an assert is failing, deleting it is a valid fix." This pattern leaked into HumanEval — the model now writes solutions that produce assertions which pass trivially, breaking the test harness.
The handler was technically correct. assert X == Y → pass is a valid AST transformation. It was semantically wrong as a teaching signal.
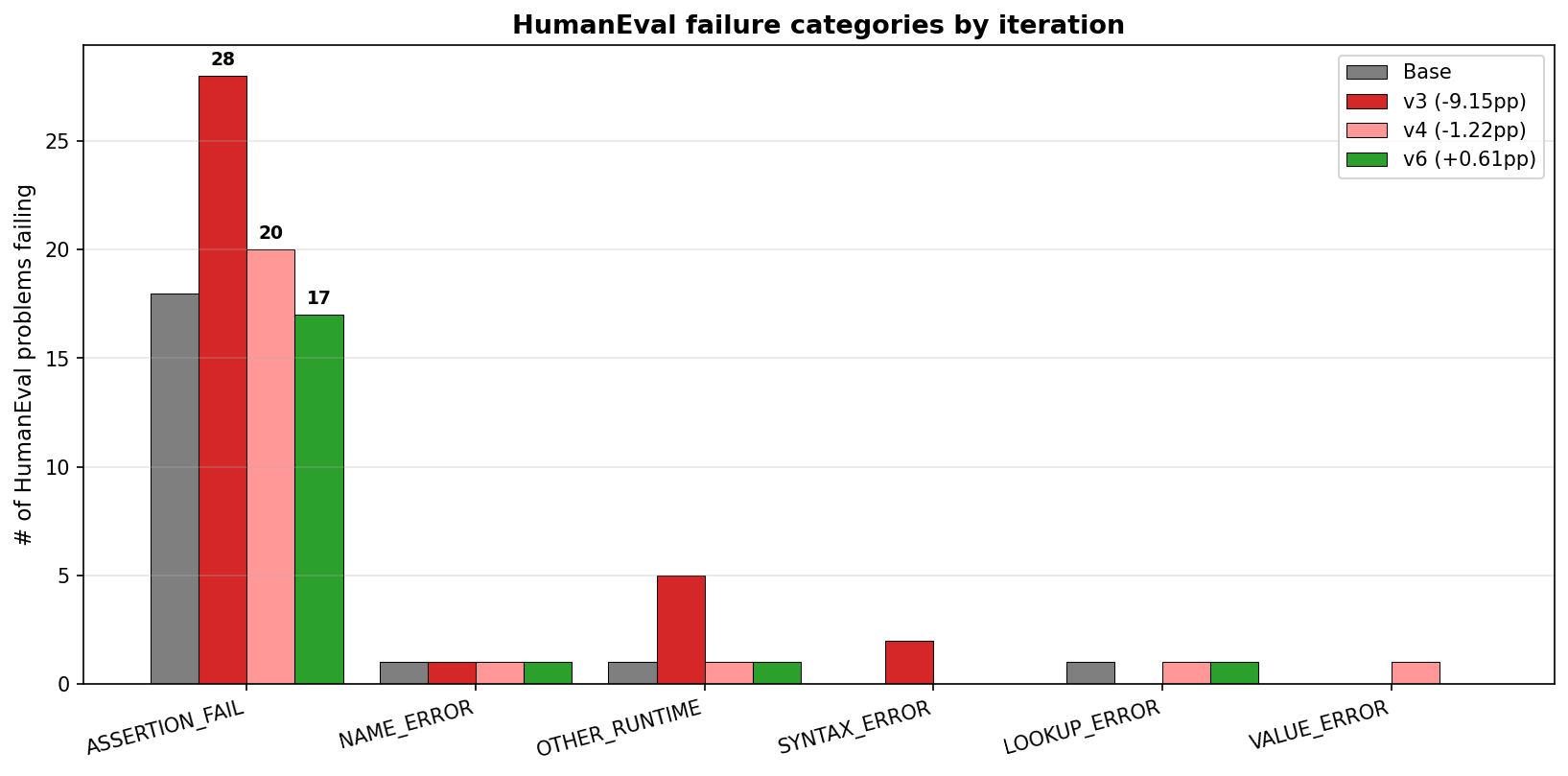
The same evaluation harness, the same 164 problems. Different chosen-sample contents teach the model different things.
Takeaway 1: chosen quality is not about syntactic correctness. It's about whether the transform teaches the right behavior. A reviewer flagged this risk before we trained — we ran the iteration anyway because a previous experiment on a smaller model had shown the AssertionError category was the largest improvement driver. Different model, different data composition, different result.
Iter v4 — -1.22pp (autopilot-certified chosen, 2,439 pairs)
We pivoted to using only chosen samples that had passed our 4-layer certification gate (the four tests above). The filter cleared 2,439 candidates. Domain mix: 93% Monte Carlo, 7% other (FFT, Async, Agentic, etc.).
HumanEval: 87.20% → 85.98%. Δ = -1.22pp. MBPP: ±0pp.
A small regression on HumanEval, no regression on MBPP. The auto-pipeline scored this as "no side-effect detected" because MBPP is the side-effect canary. But HumanEval is the main metric, and it had moved the wrong way.
So we read 5 of the lowest-coverage chosen samples by eye. All 5 had subtle bugs that the certification gate had missed:
- Sample 1 (Numerical Linear Algebra, coverage 17.5%):
import numpy as np was missing entirely. The code referenced np.eye(...), np.argmax(...), np.dot(...) throughout. Two helper functions were called that were never defined (PU_to_U, PU_to_P). The code was unrunnable. It had been certified.
- Samples 2-5 (Monte Carlo MCMC, coverages 45-71%): All four had a variation of the same bug. Inside
mcmc_sample:
for _ in range(n_samples):
state, accepted = metropolis_step(state, log_target, sigma)
if accepted:
samples.append(state) # silently drops rejected proposals
return samples
The Metropolis-Hastings algorithm requires that every step append the current state regardless of acceptance. The MCMC trace generated by this code is missing all rejected proposals, breaks the chain's stationary distribution, and produces len(samples) ≠ n_samples.
The 4-layer gate had passed all 5 of these. The semantic check confirmed the code was meaning-coherent with the prompt. The fuzz check confirmed no crashes. Neither was equipped to detect these specific logic errors.
Takeaway 2: certifying that code "runs without crashing on canonical inputs" doesn't mean it's logically correct. Tests with low branch coverage pass code that's wrong on paths they don't exercise. We had measured test_coverage_score, but our cert filter didn't require a minimum on it.
Iter v4.1 — NO-GO ×2 (AST-gate enhancements not enough)
We tried to plug the holes by adding AST-based gates to reject the patterns we'd found:
if accepted: list.append(...) — reject (the MCMC dropout pattern)_, _ = step(...) or _ = step(...) — reject (return-value discard, found in another sample's burn-in loop)- Names that aren't defined or imported — reject
test_coverage_score >= 80 — requiredadv_score >= 75 — required (existing internal quality metric)
This filtered 2,439 → 251 → 72 across two attempts. We sent 7 samples each time to an outside reviewer.
The reviewer found two more bug classes that AST gates can't detect:
def metropolis_step(current, log_target, sigma):
proposed = proposal(current, sigma)
return proposed, True # accept flag hardcoded as True
def metropolis_step(current, log_target, sigma):
proposed = proposal(current, sigma)
accepted = random.random() < acceptance_ratio(...)
return (proposed if accepted else current,)
# 1-element tuple — docstring promises (state, accepted)
Both are syntactically valid Python. Both pass any AST check we care to write. Both break the function's behavioral contract.
Takeaway 3: AST validation has a ceiling. A function's contract — "the second tuple element is the accept-status, computed from random.random() < α" — cannot be enforced by parsing alone. You have to actually execute the code with inputs that exercise the contract.
What actually fixed it: 8-layer gates (extending the existing 4 with 4 more)
We added four more layers to certification:
- Semantic AST checks for the bug patterns we'd identified —
return X, True/False as the only return path, _, _ = step(...) as a return-value discard, etc.
- Dataflow checks for state-update patterns that occur outside an
if accepted: block.
- Edge-case execution fuzz, with inputs designed to exercise the contract — for MCMC, log-target functions that produce extreme log-density values; for FFT, round-trip equality
ifft(fft(x)) ≈ x. These run as subprocesses against the candidate code and reject anything that returns NaN, Inf, or violates the invariant.
- Coverage strict —
test_coverage_score >= 80 as a hard requirement, not a soft scoring.
Layer 7 alone — the edge-case execution fuzz — rejected 74 of 227 candidates that had passed all four original layers. 33% of our existing certified pool was hiding numerical-stability bugs. Most were acceptance_ratio = exp(log_target(prop) - log_target(cur)) blowing up to inf for log-density differences of more than ~700.
After all 8 layers ran, 116 chosen samples remained out of the original 2,439.
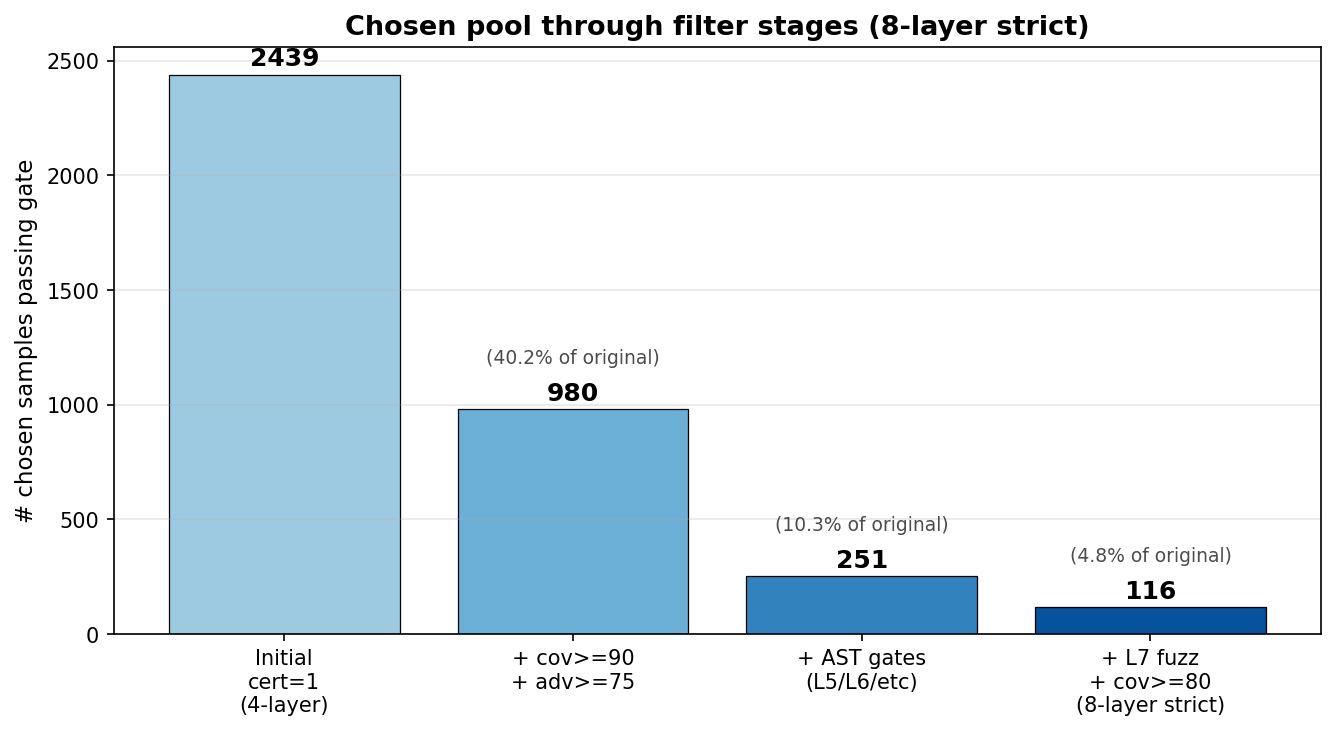
Most of the loss happens at the last step (Layer 7 fuzz + Layer 8 coverage strict).
Domain mix changed dramatically:
| Domain | iter v4 | iter v6 (8-layer strict) |
|---|
| Monte Carlo | 93% | 27% |
| Python Async | 1.5% | 32% |
| Agentic | 0% | 23% |
| Other | 5.5% | 18% |
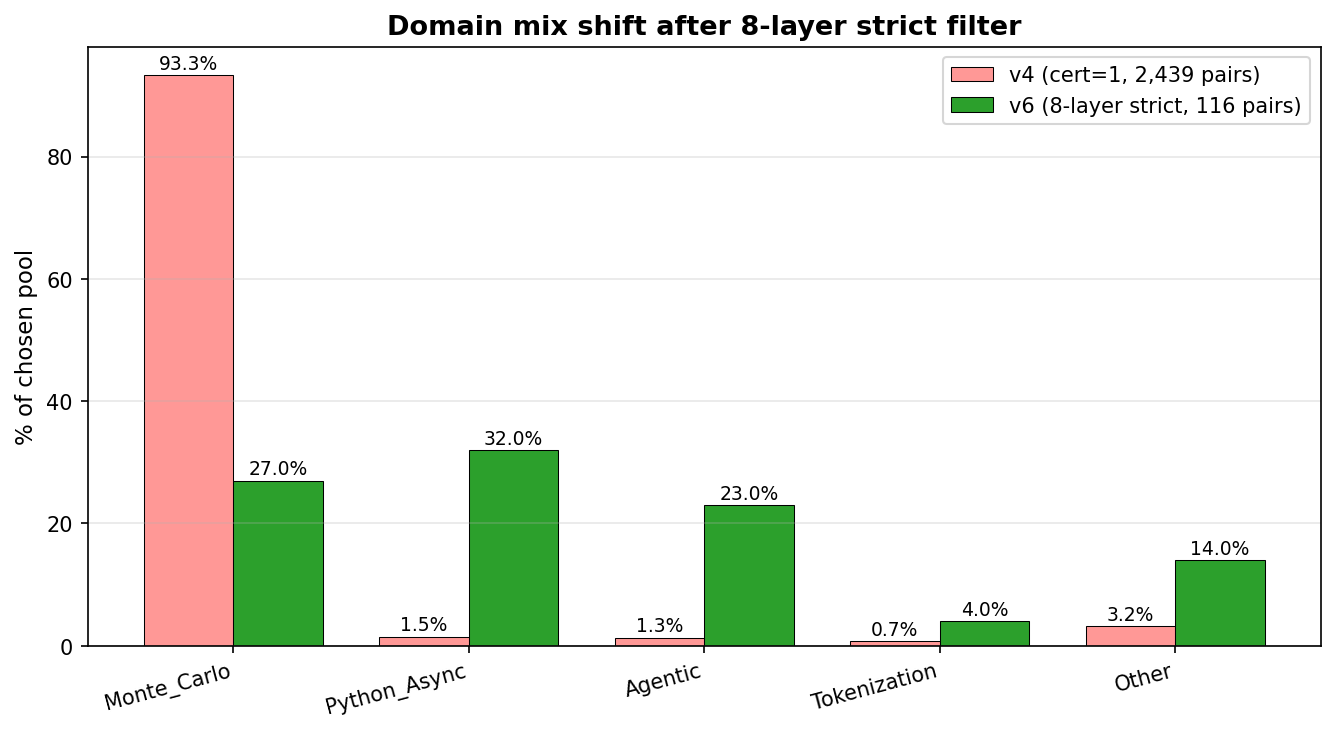
The Monte Carlo dominance was an artifact of which domain had the buggiest chosen samples in our pool, not which domain had the most chosen samples generated. After we filtered out the bugs, the distribution looked completely different.
Iter v6 — +0.61pp (recovery)
We trained on 115 pairs (one chosen sample had no compatible rejected partner in the same domain).
HumanEval: 87.20% → 87.80%. Δ = +0.61pp. MBPP: 84.82% → 84.44%. Δ = -0.39pp (within ±1pp tolerance).
| Failure category | Base | iter v6 | Δ |
|---|
| ASSERTION_FAIL | 18 | 17 | -1 |
| NAME_ERROR | 1 | 1 | 0 |
| LOOKUP_ERROR | 1 | 1 | 0 |
| OTHER_RUNTIME | 1 | 1 | 0 |
| TOTAL FAIL | 21 | 20 | -1 |
A small recovery, but worth noting:
- We trained on 1/20th the pair count of v4 (115 vs 2,439). Per-sample signal quality went up by roughly an order of magnitude.
- ASSERTION_FAIL moved -1 instead of v3's +10 or v4's +2. Same prompt distribution, same evaluation harness — different chosen-sample contents.
- No category regressed by more than +1.
Training was 3 epochs over 115 pairs (45 total steps, ~11 minutes on a single RTX 4060).
Bonus pain: deploying the LoRA to Ollama
We lost three hours on this and it's not in the LLM blog circuit yet, so it deserves a section.
Standard path:
- Train with Unsloth (4-bit base + LoRA, 16-bit save).
save_pretrained_merged(method='merged_16bit') to produce safetensors.ollama create -q Q4_K_M from the safetensors directory.ollama run.
Step 4 returned 500 Internal Server Error every single time. The server log showed:
Assertion failed: found, file llama-sampling.cpp, line 660
Six attempts to fix:
- Override
bos_token in tokenizer_config.json — still failed.
- Replace
tokenizer.json with the official Qwen one from HuggingFace — still failed.
- Run
mergekit in passthrough mode with tokenizer_source: Qwen/Qwen2.5-Coder-7B-Instruct — still failed.
- Extend
lm_head.weight and embed_tokens.weight from vocab 151,665 to 152,064 (matching the official) — still failed.
- Test the previous TIES-merged model that we'd built months ago — also failed. So this isn't iter-v6-specific; it's a structural incompatibility between Ollama 0.23.1's
ollama create GGUF pipeline and any safetensors that Unsloth (or mergekit, in our case) produces for Qwen2.5.
What worked: skip the merged-model path entirely.
# Step 1: Convert just the LoRA adapter to GGUF
python ~/llama.cpp/convert_lora_to_gguf.py \
outputs/dpo/iter1_v6/adapter_iter1_v6 \
--outfile outputs/iter1_v6_adapter.gguf
# 161 MB output
# Step 2: Modelfile attaches the adapter to the official Ollama-pulled base
cat > Modelfile_v6 <<EOF
FROM qwen2.5-coder:7b
ADAPTER ./iter1_v6_adapter.gguf
PARAMETER temperature 0.7
PARAMETER top_p 0.9
PARAMETER num_ctx 8192
EOF
# Step 3: Standard create + run
ollama create idfu-merged:iter1_v6 -f Modelfile_v6
echo "..." | ollama run idfu-merged:iter1_v6
Two non-obvious gotchas:
- The
convert_lora_to_gguf.py script reads adapter_config.json to find the base model. Unsloth's adapter_config points to unsloth/Qwen2.5-Coder-7B-Instruct-bnb-4bit, which is bnb-4bit quantized, which the converter can't dequantize. Manually edit adapter_config.json to point at Qwen/Qwen2.5-Coder-7B-Instruct (the non-quantized official base) before converting.
- Don't add a
TEMPLATE line to the Modelfile. The official base GGUF has Qwen2.5's chat template baked in. If you override it (we tried TEMPLATE """{{ .Prompt }}"""), the LoRA's expected <|im_start|>...<|im_end|> framing breaks and the model emits literal <|im_start|> tokens in its output.
The official Ollama base GGUF works because Ollama's own quantization toolchain doesn't trip the same llama-sampling bug as ollama create from-safetensors does. The ADAPTER directive lets you layer your weights on top.
Takeaway 4: when the official path works and yours doesn't, sometimes the right answer is to use the official artifact and patch your changes on top.
What we'd do differently from the start
If we were starting from scratch:
Sample chosen by eye, before training. Read 5-10 randomly selected records from the lowest 25% of test_coverage_score. Don't train until you've personally verified that level of quality is acceptable as a teaching signal. It costs 30 minutes; it could save a 5-hour training run.
Don't trust "no syntax error" as a quality signal. AST validation is a floor, not a ceiling.
Build your edge-case execution gate before you generate chosen at scale. Adversarial inputs, NaN/Inf checks, contract assertions. The 33% Layer-7 catch rate suggests this is where most signal-quality bugs live, regardless of pipeline.
Watch the failure category breakdown, not just the pass@1 delta. A -1.22pp loss with ASSERTION_FAIL +2 looks like marginal noise. The same -1.22pp with ASSERTION_FAIL +10 (as in iter v3, amplified to -9.15pp) is a structurally broken training signal. The categories tell you why.
Plan your deployment path before you train. Knowing that ollama create from arbitrary safetensors had this sampler bug would have saved us three hours.
What we ended up validating
The headline result is small: +0.61pp. But the demonstration underneath it is what matters to us.
We trained on just 115 chosen pairs (one of the 116 had no compatible same-domain rejected partner). On a 7B model. Against an evaluation set the model already passed 143/164 of. And it still moved the needle.
This says three things:
- It is possible to improve a 7B model's HumanEval pass@1 through DPO on autopilot-generated data — provided the chosen samples are actually clean. The earlier failures were not telling us "DPO doesn't work on 7B"; they were telling us "your chosen samples have bugs the eval is sensitive to."
- A clean chosen pool of ~100 pairs is enough for a measurable improvement at this scale. The training run was 11 minutes on a single RTX 4060. Scale is not the bottleneck right now.
- The bottleneck is generating chosen samples that survive the gate. We started with 2,439 cert=1 candidates and ended up with 116. The gate is doing its job — but it means our chosen-sample pipeline is producing roughly 95% logically-flawed output that we don't notice until we look hard.
What's next
The current chosen_grade=1 pool (the 8-layer-strict cohort) has 116 records. We need ~500 before iter 2 is worth attempting at scale. The autopilot is running with the new gates inline now, so newly-generated samples get the strict evaluation automatically. We've biased the domain selector toward Pytest_Traceback_Driven_Code_Repair (which currently has 0 chosen-grade samples — the bootstrap-domain frontier).
The harder problem ahead is chosen-sample generation throughput, not training. Most autopilot output doesn't survive the 8-layer filter. Layer 7 (edge-case execution fuzz) alone rejects roughly a third; Layer 8 (test_coverage_score >= 80) eats most of the rest. Growing the pool by an order of magnitude requires either pushing the autopilot to produce higher-baseline-quality samples in the first place, or expanding bootstrap coverage in domains where current cert=1 is near zero.
We'll keep collecting. When we have iter 2 results to compare against — bigger pool, same gate — we'll report back here. If +0.61pp is the floor, it's a useful floor; if it scales linearly with pool size, that's a different story.
Diagnostic for anyone running into the same wall
If you're running DPO and your improvements are stuck around the noise floor, the diagnostic is short: read 5 chosen samples from the bottom 25% of your highest-quality-tier pool, by eye, like a code reviewer would. The bugs are usually there. The question is whether your gate caught them.
Comments and counter-experiences welcome. The four-iteration arc here cost us ~36 hours of GPU-and-engineering time; if you've run something similar and seen different patterns, I'd love to hear.