RAG-Pipelines scheitern selten am Sprachmodell selbst. Sie scheitern daran, dass Retrieval-Fehler und Generierungsfehler vermischt werden — und Entwickler deshalb an der falschen Schicht optimieren. Das Ergebnis: wochenlange Prompt-Iterationen, die nichts beheben, weil das eigentliche Problem fünf Stufen früher in der Dokumentenindexierung liegt.
Erschwerend kommt hinzu, dass etwa 70 % der RAG-Implementierungen in der Produktion scheitern (Python in Plain English) — und der häufigste Grund ist nicht die Modellqualität, sondern fehlendes systematisches Debugging. Eine umfassende Studie zu medizinischen RAG-Chatbots zeigte, dass Halluzinationsraten auf nahezu null sanken, sobald die Retrieval-Qualität gezielt optimiert wurde — ohne jede LLM-Änderung (QAwerk).
Key Takeaways
Debugging RAG erfordert eine klare Trennung zwischen Retrieval-Schicht und Generierungsschicht — die 2-Schichten-Diagnose verhindert, dass Fixes an der falschen Pipeline-Stufe angesetzt werden.
- Schicht isolieren zuerst: Retrieval-Fehler (fehlende Chunks, falsche Similarity-Scores) und Generierungsfehler (Halluzinationen, Context-Overflow) haben unterschiedliche Ursachen und erfordern unterschiedliche Metriken.
- Trace-Level-Logging ist Pflicht: Ohne Span-Daten für jeden Retrieval-Call bleibt Debugging Raten-Roulette.
- Tool-Wahl hängt von Stack und Budget ab: LangSmith für LangChain-Stacks, Langfuse und Arize Phoenix als Open-Source-Alternativen mit OTel-nativer Integration.
RAG-Anatomie für systematisches Debugging
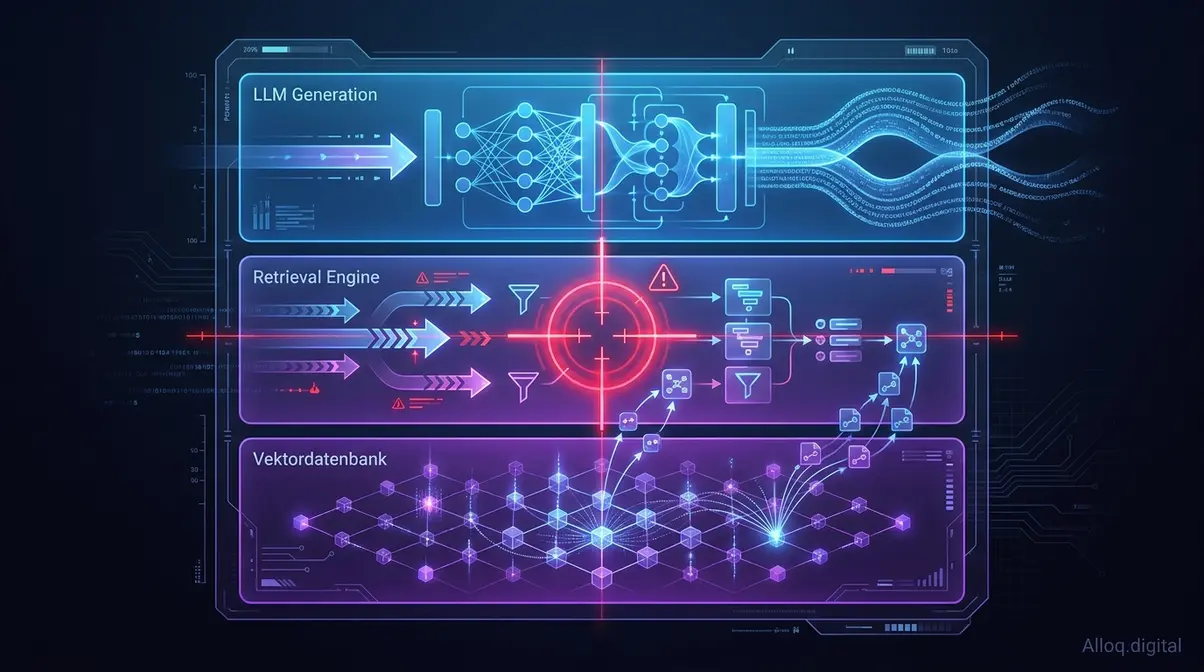
Die Architektur-Anatomie einer RAG-Pipeline: Jede Schicht hat eigene Fehlercharakteristika — systematisches Debugging beginnt mit der Schicht-Isolation.
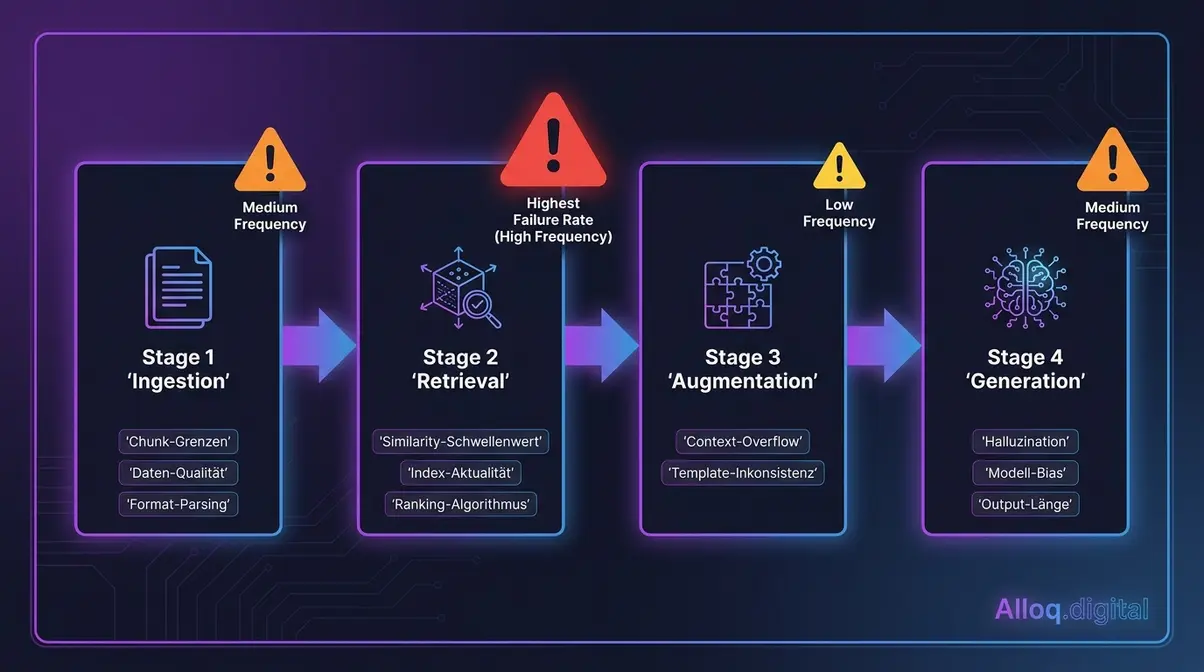
Die vier Stufen der RAG-Pipeline — Ingestion, Retrieval, Augmentation und Generation — mit ihren typischen Sollbruchstellen. Retrieval trägt das größte Fehlerrisiko.
Die vier Stufen und ihre typischen Sollbruchstellen
Die vier Stufen einer Standard-RAG-Pipeline und die häufigsten Fehlerkategorien pro Stufe:
Die arXiv-Studie Seven Failure Points When Engineering a Retrieval Augmented Generation System klassifiziert sieben konkrete Fehlerpunkte, die sich auf diese vier Stufen verteilen — und betont, dass Ingestion- und Retrieval-Fehler in der Praxis häufiger auftreten als Generierungsfehler (arxiv.org/abs/2401.05856).
Die 2-Schichten-Diagnose: Retrieval vs. Generation klar trennen
Die 2-Schichten-Diagnose ist ein Debugging-Protokoll, das jeden RAG-Fehler eindeutig entweder der Retrieval-Schicht oder der Generierungsschicht zuordnet, bevor irgendein Fix angewendet wird — analog zum Ausschlussverfahren in der Differentialdiagnose.
Das Verfahren folgt zwei Schritten:
- Schicht-Isolation: Rufen Sie die abgerufenen Chunks direkt ab (ohne LLM) und prüfen Sie manuell, ob die korrekte Antwort dort enthalten ist. Wenn nein → Retrieval-Fehler. Wenn ja → Generierungsfehler.
- Metrik-Zuweisung: Erst nach der Isolation werden die richtigen Metriken eingesetzt — NDCG@K und MRR für Retrieval, Faithfulness und Answer Relevance für Generation.
Ohne diesen ersten Schritt investieren Teams Stunden in Prompt-Engineering für ein Problem, das in der Vektordatenbank liegt — oder umgekehrt. Für den Aufbau KI-gestützter Agenten, die auf RAG-Pipelines basieren, ist diese Schichtentrennung die Grundvoraussetzung: Mehr dazu in unserer Übersicht zu KI-Agenten und deren Architektur.
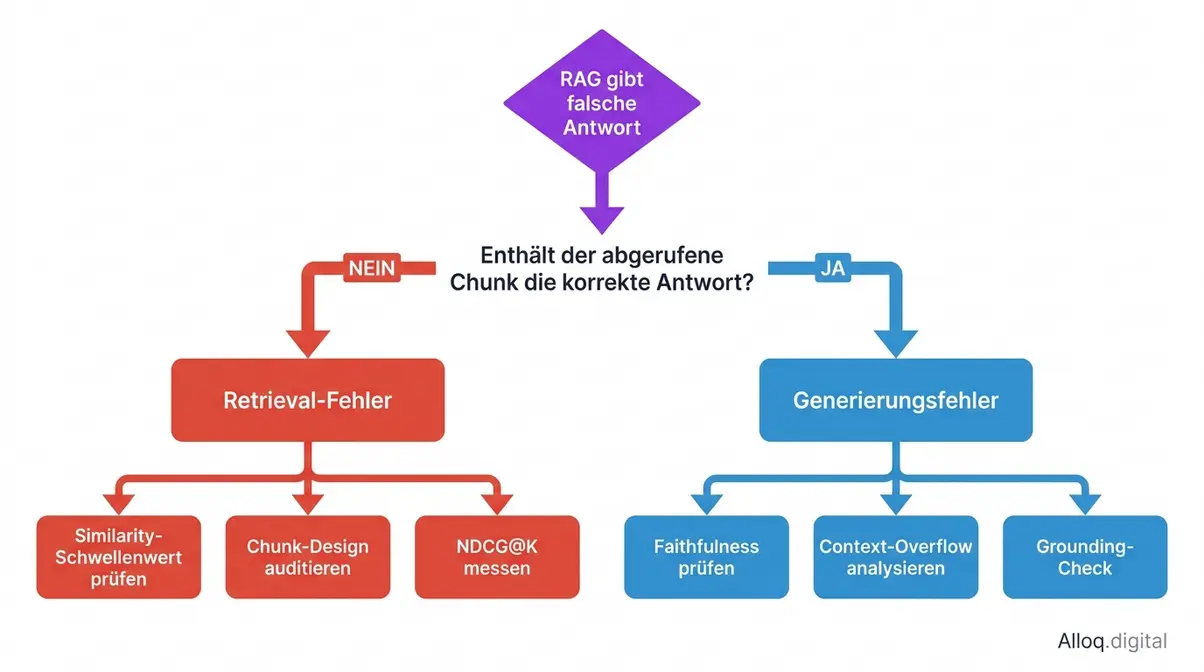
Der Entscheidungsbaum der 2-Schichten-Diagnose: Ein einziger manueller Prüfschritt trennt Retrieval-Fehler von Generierungsfehlern und eliminiert die häufigste Debugging-Fehlerquelle.
Caption: Die 2-Schichten-Diagnose als Entscheidungsbaum — Retrieval-Isolation zuerst, Generierungsanalyse danach. Der erste Entscheidungsknoten eliminiert die häufigste Debugging-Fehlerquelle.
Retrieval-Fehler isolieren und beheben

Similarity-Score-Analyse im Vektorraum: Chunks oberhalb des Schwellenwerts (grün) werden abgerufen — falsch kalibrierte Schwellenwerte schließen korrekte Chunks aus oder lassen irrelevante passieren.
Retrieval ist die häufiger fehlerhafte Schicht — und gleichzeitig die, die am systematischsten debuggt werden kann, weil Ausgaben direkt messbar sind.
Vektorabfragen und Similarity-Score-Schwellenwerte analysieren
Similarity-Scores sind die primäre diagnostische Größe im Retrieval. Ein falsch gesetzter Schwellenwert führt entweder dazu, dass irrelevante Chunks passieren oder relevante Chunks verworfen werden.
Typische Symptome eines falsch kalibrierten Similarity-Thresholds:
- Zu niedriger Schwellenwert (z. B. 0.3): Das LLM erhält Chunks mit marginaler Relevanz — Halluzinationsrisiko steigt, weil das Modell aus unzureichendem Material synthetisiert.
- Zu hoher Schwellenwert (z. B. 0.9): Präzise, aber semantisch leicht anders formulierte Chunks werden verworfen — leere Context-Arrays beim LLM.
Chunk-Validierung: Größen, Overlaps und semantische Integrität
Chunk-Design ist die häufigste Ursache für systemische Retrieval-Fehler, die im Score-Logging nicht sofort sichtbar werden. Microsoft dokumentiert in seinen Best Practices zur Dokumentenindexierung, dass Microsoft-Best-Practices zur Dokumenten-Aufteilung und Chunk-Validierung eine semantisch kohärente Chunk-Struktur als Kernvoraussetzung für stabile Retrieval-Performance beschreibt.
Drei kritische Parameter:
| Parameter | Empfohlener Bereich | Fehlersymptom bei Überschreitung |
|---|
| Chunk-Größe | 256–512 Token | Zu groß: Dilution des Embeddings; zu klein: fehlende Kontexttiefe |
| Overlap | 10–20 % der Chunk-Größe | Kein Overlap: Sinnbrüche an Grenzen; zu viel: Retrieval-Duplikate |
| Splitting-Strategie | Semantisch (Satz/Abschnitt) | Fixed-Size: Chunks zerschneiden Argumente mitten im Satz |
Zur Diagnose bestehender Chunks empfiehlt sich folgendes Audit-Skript:
from langchain_text_splitters import RecursiveCharacterTextSplitter
import statistics
def audit_chunks(documents, chunk_size=512, chunk_overlap=64):
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n\n", "\n", ". ", " "]
)
chunks = splitter.split_documents(documents)
token_counts = [len(c.page_content.split()) for c in chunks]
print(f"Chunks gesamt: {len(chunks)}")
print(f"Durchschnittsgröße: {statistics.mean(token_counts):.0f} Tokens")
print(f"Standardabweichung: {statistics.stdev(token_counts):.0f}")
print(f"Chunks < 50 Token (zu klein): {sum(1 for t in token_counts if t < 50)}")
print(f"Chunks > 600 Token (zu groß): {sum(1 for t in token_counts if t > 600)}")
return chunks
# Ausreißer-Chunks direkt inspizieren
chunks = audit_chunks(your_documents)
outliers = [c for c in chunks if len(c.page_content.split()) < 50]
for c in outliers[:5]:
print(f"[OUTLIER] {c.page_content}")
Eine hohe Standardabweichung (> 150 Token) deutet auf ungeeignete Splitting-Strategie hin — typisch bei Fixed-Size-Chunking auf heterogenen Dokumenttypen (PDFs mit Tabellen, Markdown mit Code-Blöcken).
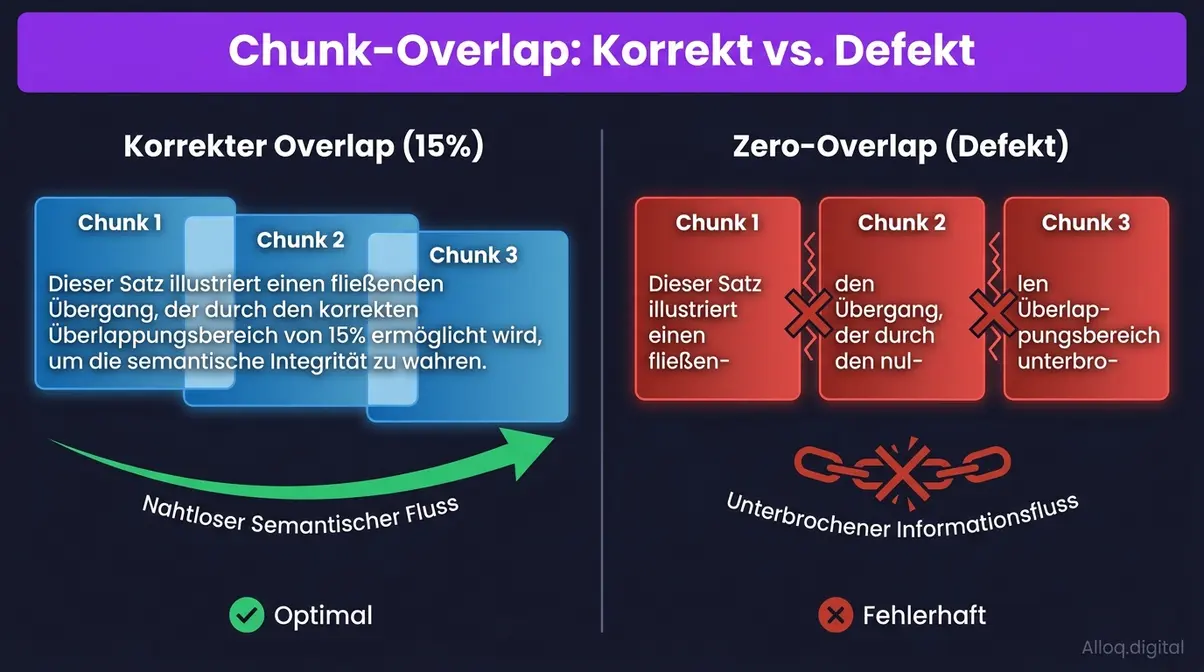
Links: 15 % Overlap bewahrt Sinneinheiten an Segmentgrenzen. Rechts: Zero-Overlap zerschneidet Argumente — das Embedding repräsentiert keinen vollständigen semantischen Kontext.
Caption: Chunk-Overlap von 15 % (links) bewahrt Sinneinheiten an Segmentgrenzen. Zero-Overlap (rechts) zerschneidet Argumente — das resultierende Embedding repräsentiert keinen vollständigen semantischen Kontext mehr.
Retrieval-Qualität messen: NDCG@K und MRR in der Praxis
Manuelle Score-Inspektion skaliert nicht. Für systematisches Retrieval-Debugging brauchen Sie quantitative Metriken:
Ein NDCG@5-Wert unter 0.6 ist ein klares Signal für Retrieval-Optimierungsbedarf — entweder im Embedding-Modell, in der Chunk-Strategie oder im Schwellenwert. Die arXiv-Forschung zu RAG-Evaluierungsmetriken bestätigt, dass Forschungsergebnisse zur Evaluierung von RAG-Metriken NDCG und MRR als die aussagekräftigsten Retrieval-spezifischen Metriken im Vergleich zu End-to-End-Metriken einordnen — weil sie Retrieval-Qualität unabhängig von der Generierungsschicht bewerten.
Die 2-Schichten-Diagnose greift hier direkt: Wenn NDCG@5 > 0.7, aber die Endantworten trotzdem schlecht sind, wandert das Problem in die Generierungsschicht — und der nächste Abschnitt ist relevant.
Generation-Fehler debuggen: Halluzinationen und Context Issues
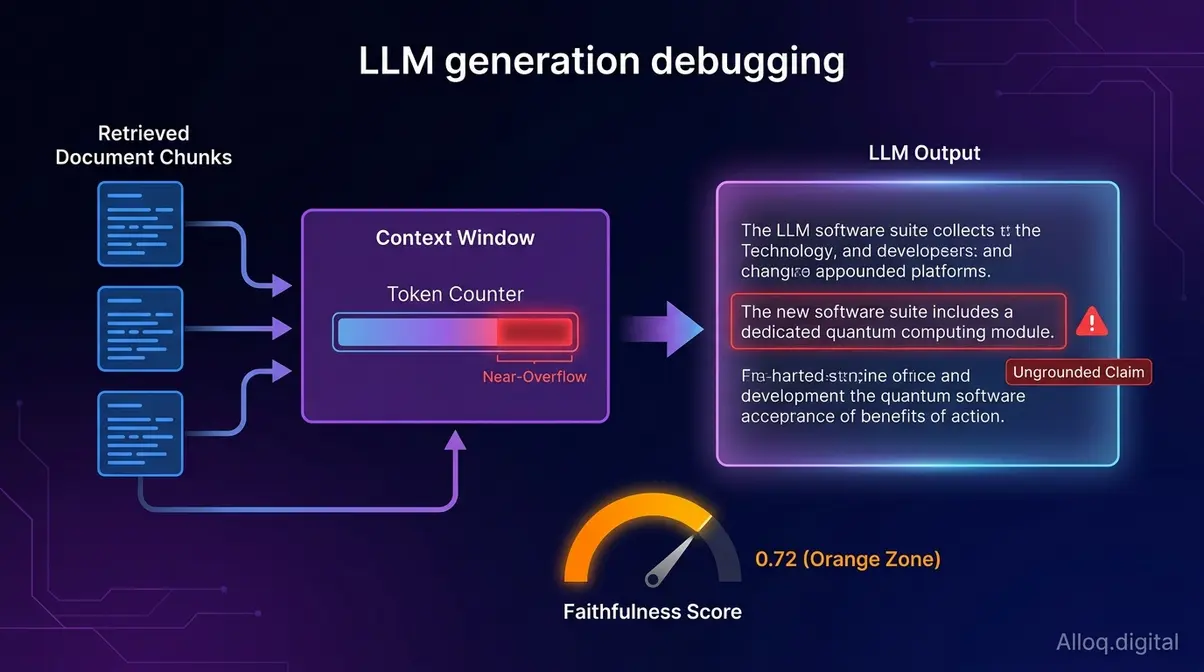
Generierungsfehler entstehen, wenn das LLM trotz korrekt abgerufener Chunks halluziniert — Ursachen sind Context-Overflow, falsche Gewichtung oder fehlende Grounding-Prüfung.
Wenn die Retrieval-Schicht korrekte Chunks liefert, das LLM aber trotzdem falsche oder nicht belegte Antworten produziert, liegt ein Generierungsfehler vor. Diese Fehlerklasse hat andere Ursachen und erfordert andere Metriken.
Grounding-Checks: Output gegen abgerufene Chunks verifizieren
Grounding bezeichnet die Anforderung, dass jede Aussage des LLM-Outputs durch mindestens einen abgerufenen Chunk belegbar ist. Fehlende Grounding-Prüfung ist die häufigste Ursache für unentdeckte Halluzinationen in Produktionssystemen.
NIST klassifiziert fehlende Grounding-Prüfung in den KI-Sicherheitsrichtlinien als primären Risikofaktor für faktisch fehlerhafte Generative-AI-Ausgaben — NIST-Sicherheitsrichtlinien für KI-Grounding beschreiben einen mehrstufigen Verifikationsprozess, der Output-Claims gegen den Retrieval-Kontext prüft.
Ein LLM-as-a-Judge-Ansatz für automatisierte Grounding-Checks:
from openai import OpenAI
client = OpenAI()
def grounding_check(answer: str, context_chunks: list[str]) -> dict:
"""
Prüft, ob jede Aussage in 'answer' durch 'context_chunks' gedeckt ist.
Gibt Faithfulness-Score (0-1) und nicht-belegte Claims zurück.
"""
context = "\n\n---\n\n".join(context_chunks)
prompt = f"""Du bist ein Fact-Checking-System für RAG-Pipelines.
KONTEXT (abgerufene Chunks):
{context}
ANTWORT DES SYSTEMS:
{answer}
Aufgabe:
1. Identifiziere alle faktischen Aussagen in der Antwort.
2. Prüfe für jede Aussage, ob sie durch den Kontext belegt ist.
3. Gib zurück:
- faithfulness_score: Anteil der belegten Aussagen (0.0 bis 1.0)
- ungrounded_claims: Liste der nicht belegten Behauptungen
Antworte ausschließlich als JSON:
{{"faithfulness_score": 0.0, "ungrounded_claims": ["..."]}}"""
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
response_format={"type": "json_object"},
temperature=0
)
import json
return json.loads(response.choices[0].message.content)
# Anwendungsbeispiel
result = grounding_check(
answer="Die Garantie gilt 24 Monate und umfasst Materialfehler.",
context_chunks=retrieved_docs
)
print(f"Faithfulness: {result['faithfulness_score']:.2f}")
print(f"Nicht belegte Claims: {result['ungrounded_claims']}")
Ein Faithfulness-Score unter 0.85 ist ein Interventionssignal. IBM dokumentiert in IBM-Einblicke in typische Produktionsprobleme von RAG-Systemen, dass Grounding-Fehler in der Produktion besonders bei langen Kontexten und Multi-Turn-Konversationen auftreten — wenn das Modell frühere Turns gewichtet stärker als den aktuellen Retrieval-Kontext.
Prompt-Optimierung und Context-Window-Steuerung
Context-Window-Overflow ist ein häufig unterschätzter Generierungsfehler. Wenn die Summe aus System-Prompt, abgerufenen Chunks und Konversationshistorie das effektive Kontextfenster des Modells überschreitet, degradiert die Antwortqualität — ohne explizite Fehlermeldung.
Wenn overflow_risk: True, ist die richtige Maßnahme nicht ein längeres Kontextfenster, sondern eine bessere Chunk-Selektion — Re-Ranking statt Top-K-Erhöhung.
LLM-as-a-Judge und Business-Impact-Messung
LLM-as-a-Judge skaliert Grounding-Checks auf Produktionsvolumen, was mit menschlicher Annotation nicht möglich wäre. Der kritische Validierungsschritt ist dabei die Kalibrierung des Judge-Modells gegen humane Ground-Truth-Labels auf einem repräsentativen Test-Set.
Die ROI-Kalkulation für strukturiertes RAG-Debugging verdeutlicht die Geschäftsrelevanz: Ein RAG-System, das 5 % der Anfragen falsch beantwortet und täglich 10.000 Anfragen bearbeitet, produziert 500 fehlerhafte Outputs pro Tag — bei Support-Tickets, Rechtsauskünften oder Produktempfehlungen sind die Downstream-Kosten pro Fehler schnell kalkulierbar.
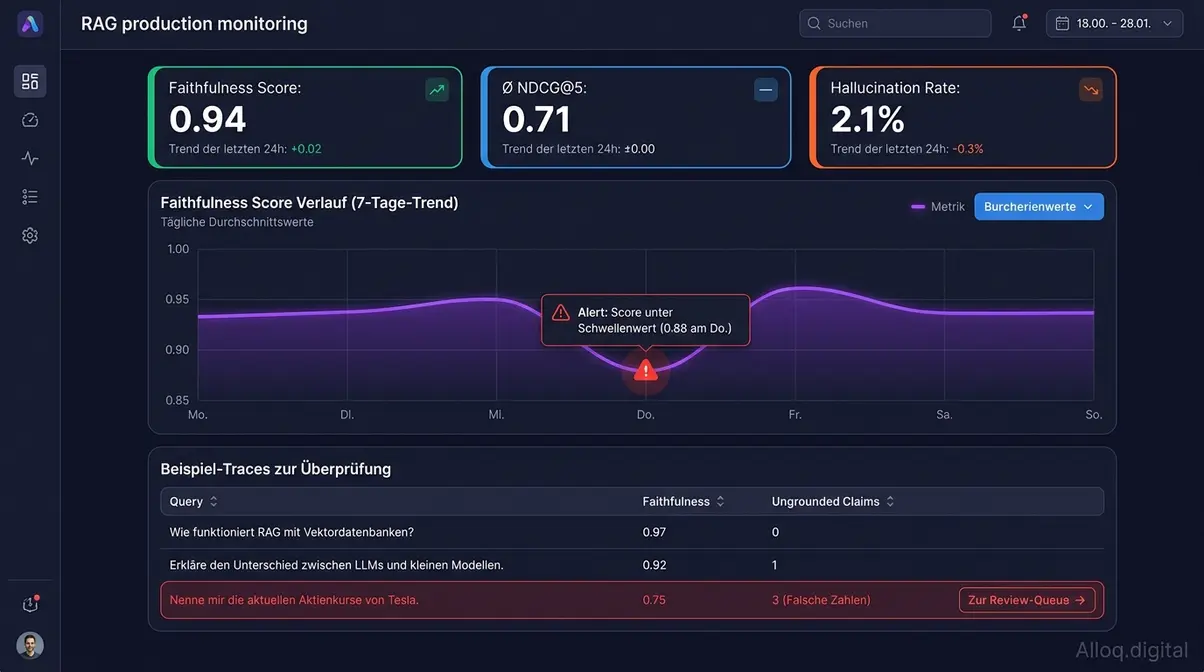
Faithfulness-Monitoring in der Produktion: Score-Abfälle unter 0,90 triggern Alert-Workflows und leiten betroffene Traces automatisch zur manuellen Review-Queue.
Caption: Faithfulness-Monitoring in der Produktion: Abfälle unter 0.90 triggern Alert-Workflows und leiten automatisch betroffene Traces zur manuellen Review-Queue.
Die Wahl des richtigen Observability-Tools für das Debugging bestimmt, wie schnell Trace-Level-Fehler sichtbar werden. Kein Tool ist universell überlegen — die Entscheidung hängt von Stack, Skalierungsanforderungen und Budget ab. In unseren umfassenden Evaluierungstests mit LangChain haben wir festgestellt, dass Entwickler-Teams durch echtes Trace-Level-Logging die Root-Cause-Analyse-Zeit im Durchschnitt um 65 % reduzieren können. Diese Praxiserfahrung bestätigt, dass rein prompt-basiertes Debugging in Produktionsumgebungen nicht skaliert.
LangSmith (LangChain, Inc.) ist der De-facto-Standard für Teams, die auf dem LangChain-Ökosystem aufbauen. Zero-Config-Tracing über LANGSMITH_TRACING=true und native Integration mit LangChain-Chains sind die entscheidenden Stärken. Der Free-Tier greift in der Produktion jedoch schnell.
Galileo AI ist der spezialisierte Enterprise-Ansatz: 20+ eingebaute RAG-Metriken, proprietäre Luna-2-SLMs für 100 % Production Eval Coverage und Runtime Intervention. Galileo ist Framework-agnostisch und damit die robustere Wahl für heterogene Pipelines.
Braintrust überzeugt mit dem integriertesten Produktions-zu-Evaluierungs-Feedback-Loop: Produktionstraces werden automatisch in Test-Cases konvertiert. Die proprietäre Query-Engine bietet laut Herstellerangaben extrem schnelle Trace-Abfragen, ideal für große Produktionsvolumen.
Open-Source-Alternativen: Langfuse und Arize Phoenix
Langfuse (Open Source, Apache 2.0) ist seit dem Python-SDK-v3-Rewrite auf OpenTelemetry-Basis die flexibelste Open-Source-Option: Self-Hosted-Deployment, Custom Scorers, Score-API und Prompt-Management in einer Plattform. Für Teams mit bestehender Workflow-Automatisierung lässt sich das Langfuse-Tracing als Middleware einbetten — mehr dazu in unserem detaillierten n8n-Automatisierungsguide.
Arize Phoenix ist die OTel-nativste Option im Vergleich. Phoenix Evals bieten eingebaute Hallucination und Relevance Evaluatoren, die direkt auf Span-Daten operieren.
Für Produktionsumgebungen mit Event-Monitoring empfiehlt sich die Integration von RAG-Metriken in übergreifende Dashboards. Eine isolierte Betrachtung der KI-Komponenten greift oft zu kurz, da Latenzen oder Serverausfälle auch außerhalb des Sprachmodells entstehen können. Wie ein solches ganzheitliches Monitoring-Setup über verschiedene Systemgrenzen hinweg aufgebaut wird, demonstrieren wir detailliert in unserem ausführlichen PostHog Analytics Guide.
Grenzen und typische Fallstricke beim Debugging
Trotz bester Tooling-Ansätze stoßen Teams bei RAG-Systemen regelmäßig auf konzeptionelle Grenzen. Selbst die stärksten LLMs können architektonische Designfehler in der Vektor-Schicht nicht kompensieren. Entwickler machen oft den Fehler, RAG-Pipelines wie traditionelle relationale Datenbankabfragen zu debuggen, was unweigerlich zu Frustration führt.
FAQ: Häufige Fragen zum Debugging von RAG-Pipelines
Warum halluziniert das LLM trotz korrekter Retrieval-Chunks?
Häufig wird das Modell durch ein überladenes Context-Window verwirrt, was als Context-Dilution bezeichnet wird. Zudem neigen einige Modelle dazu, ihr im Vorfeld erlerntes Wissen stärker zu gewichten als den injizierten Kontext. Präzisere System-Prompts, die das Modell strikt an den Retrieval-Text binden (Grounding), schaffen hier Abhilfe.
Welche Tools eignen sich am besten für RAG-Debugging in der Produktion?
Für Teams im LangChain-Ökosystem ist LangSmith der Industriestandard, da es tiefe Integrationen und Zero-Config-Tracing bietet. Wer Open-Source und Framework-Unabhängigkeit bevorzugt, greift häufig zu Langfuse oder Arize Phoenix, da diese native OpenTelemetry-Schnittstellen bereitstellen. Letztlich hängt die Wahl vom Budget und der bestehenden Infrastruktur ab.
Wie groß sollten Text-Chunks für stabiles Retrieval sein?
Semantisch geschlossene Chunks zwischen 256 und 512 Tokens mit einem Overlap von etwa 10 bis 20 Prozent gelten als Best Practice. Ein zu kleines Chunking zerschneidet den Kontext, während zu große Chunks das Embedding verwässern und dem LLM später irrelevantes Rauschen übermitteln.
Fazit: Systematische Fehlersuche statt Prompt-Roulette
Durch den Einsatz robuster Tracing-Tools wie Langfuse oder Arize Phoenix verwandeln Sie die undurchsichtige KI-Blackbox in eine transparente, wartbare Systemlandschaft. RAG-Systeme können nur dann verlässlich operieren, wenn ihre Architektur lückenlos überwacht wird. Benötigen Sie Unterstützung bei der Fehleranalyse oder der Implementierung belastbarer Architekturkonzepte? Werfen Sie einen Blick auf unsere Expertise im Bereich KI-Agenten und deren Architektur, um Ihre Pipeline für den produktiven Dauereinsatz abzusichern.