I spend too much time switching between browser tabs to keep up with tech news. Hacker News in one tab. A handful of subreddits in another. lobste.rs in a third. The context switching adds up.
So I built grokfeed, a terminal feed reader that pulls all three into one scrollable feed, ranked by a time-decayed score.
Why the terminal?
A browser tab has infinite surface area for distraction. A terminal window has exactly as much as you give it.
I also wanted something I could leave running in my terminal and glance at without leaving my editor. A TUI fits that workflow better than anything browser-based.
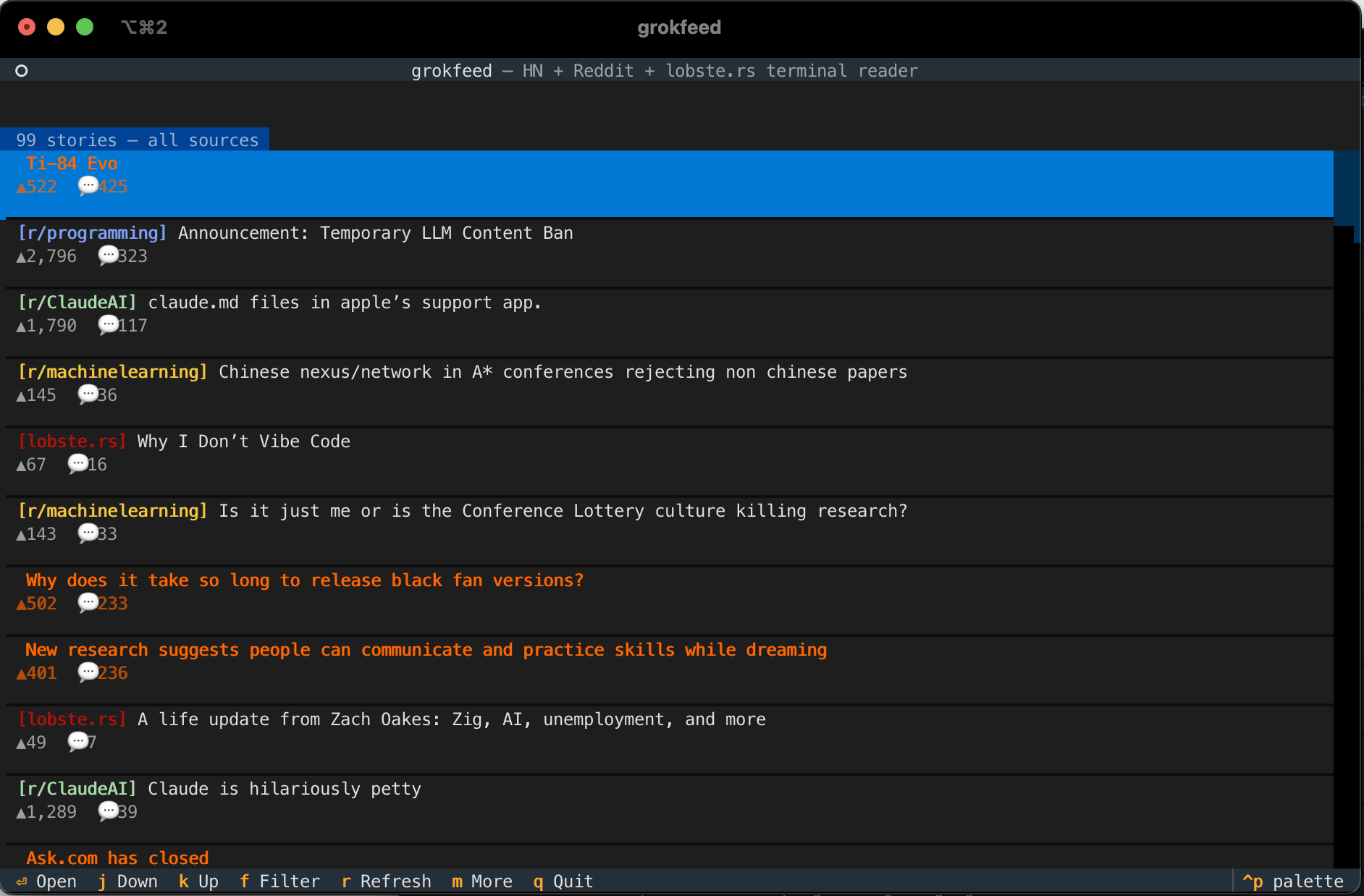
grokfeed: main feed.
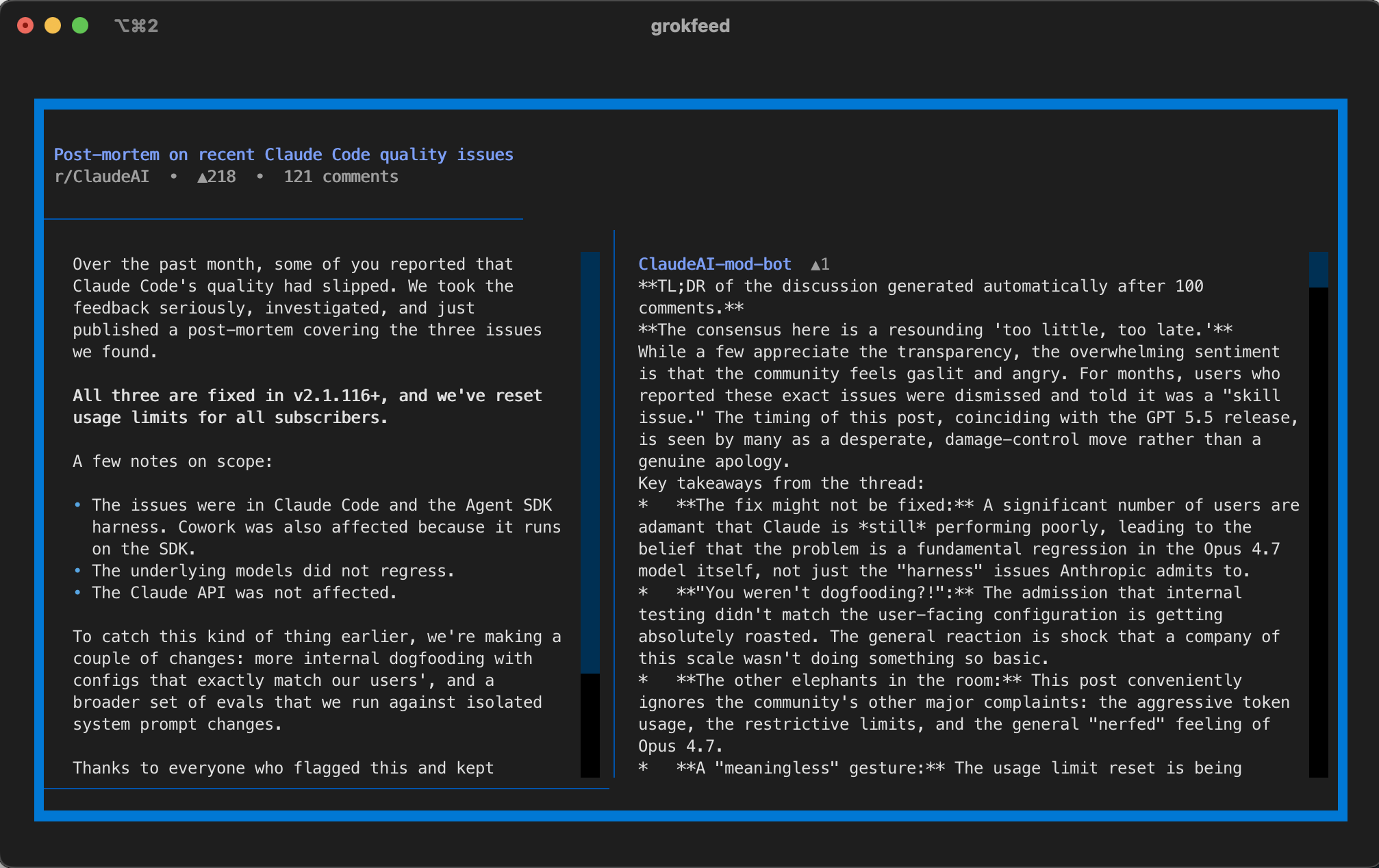
grokfeed: Post modal with comments.
Why Textual?
Textual is a Python TUI framework built on top of Rich.
It gives you:
- CSS-like layouts
- Reactive state
- Async workers
- A proper widget model
All things you'd otherwise build manually with curses or urwid but the killer feature for this project was async workers.
Textual lets you run coroutines in the background without blocking the UI, which matters when you're fetching from three APIs simultaneously.
Fetching from three sources concurrently
The feed loads Hacker News, Reddit, and lobste.rs concurrently using asyncio.gather:
hn_task = asyncio.create_task(fetch_hn_stories_by_ids(hn_ids, client))
reddit_task = asyncio.create_task(
fetch_reddit_posts(
self.config.subreddits,
self.config.reddit_post_count,
client,
)
)
lobsters_task = asyncio.create_task(
fetch_lobsters_posts(
self.config.lobsters_post_count,
client,
)
)
hn_stories, (reddit_posts, after), lobsters_posts = await asyncio.gather(
hn_task,
reddit_task,
lobsters_task,
)
Hacker News is the awkward one here.
The Firebase API returns story IDs first, then requires a separate request per story. Fetching 30 stories means 30 additional HTTP requests.
To avoid hammering the API, requests are bounded with a semaphore:
sem = asyncio.Semaphore(10)
async def _bounded(item_id: int) -> Story | None:
async with sem:
return await _fetch_item(client, item_id)
results = await asyncio.gather(*[_bounded(i) for i in ids])
The full initial load usually takes around 2–3 seconds on a normal connection.
Ranking stories from different sources
Once you merge stories from three platforms, ranking becomes tricky.
Raw scores don't work.
A Hacker News post can hit 1000+ points.
A lobste.rs front-page story might have 50.
But a lobste.rs story with 50 points is extremely popular.
The solution was to normalize scores within each source before combining them:
for source_items in groups.values():
scores = [i["score"] for i in source_items]
lo, hi = min(scores), max(scores)
span = hi - lo or 1
for item in source_items:
norm = (item["score"] - lo) / span
...
This maps scores into a 0–1 range:
- top story in each source → 1.0
- bottom story → 0.0
Now sources compete on equal footing.
Time decay
Normalization alone creates another problem:
An old Hacker News post sitting at the top of its batch still gets a normalized score of 1.0, even if it's three days old.
So the ranking adds exponential decay:
score=norm×e^(−λ×age_in_hours)
With DECAY_LAMBDA = 0.04, the half-life is roughly 17 hours.
That means:
- after ~24 hours → ranking power is heavily reduced
- after 48 hours → ~14% remains
- after 72 hours → ~5% remains
Implementation:
created_at = item.get("created_at") or now
age_hours = max(0.0, now - created_at) / 3600
item["_norm_score"] = norm * math.exp(
-DECAY_LAMBDA * age_hours
)
The or now fallback matters.
Without it, items missing timestamps (for example from an old cache) would be treated like 50-year-old posts and effectively disappear from ranking.
Each source exposes timestamps differently:
- Hacker News → Unix timestamp in time
- Reddit → created_utc
- lobste.rs → ISO 8601 string
Marking posts as seen
Opening a post dims its title in the feed so you can instantly see what you've already read.
Seen state persists across restarts in ~/.grokfeed/seen.json.
Format:
{
"43721": 1746190000.0,
"43688": 1746188400.0
}
Entries older than 24 hours are automatically pruned:
SEEN_TTL_SECONDS = 86_400
def load_seen() -> set[str]:
data: dict[str, float] = json.loads(SEEN_PATH.read_bytes())
cutoff = time.time() - SEEN_TTL_SECONDS
return {
pid for pid, ts in data.items()
if ts >= cutoff
}
def mark_seen(post_id: str) -> None:
data = {
pid: ts for pid, ts in data.items()
if ts >= cutoff
}
data[post_id] = time.time()
SEEN_PATH.write_text(json.dumps(data))
In the UI, seen is implemented as a Textual reactive:
seen: reactive[bool] = reactive(False)
def render(self) -> str:
title = (
f"[dim]{self.story_title}[/]"
if self.seen
else self.story_title
)
Changing the value automatically re-renders the row without rebuilding the list.
Config and caching
Configuration lives at: ~/.grokfeed/config.toml
Example:
subreddits = ["programming", "ClaudeAI", "machinelearning"]
hn_story_count = 30
reddit_post_count = 15
lobsters_post_count = 25
cache_ttl_minutes = 10
The feed itself is cached in: ~/.grokfeed/cache.json
If the cache is still fresh on launch, the app loads instantly and becomes usable in under a second. Pressing r bypasses the cache and refreshes everything.
Install
brew tap emarkou/grokfeed
brew install grokfeed
pip install grokfeed
pipx install grokfeed
Then run:
grokfeed
What's next?
Planned features:
- Keyword filters
- Saved searches
- Offline reading mode
- RSS feeds
- Newsletter support
Source code: github.com/emarkou/grokfeed
Feedback & contributions are very welcome!