
AI-assisted development has a quiet failure mode: the assistant that creates the pattern often becomes the assistant that reviews it.
When you and Claude work inside the same session, you drift together. The review criteria shift with the assistant's habits. After enough sessions, the same assistant that wrote the hollow function body is also the one approving the pull request. There is no external reference point — unless you build one.
That is the problem AI-SLOP Detector v3.6.0 addresses with the Claude Code skill.
Every time you run /slop inside a session, the scan result is recorded to a project-scoped history. When enough re-scan evidence accumulates, bounded self-calibration adjusts the detection weights for your codebase — automatically, without a manual command. The scanner does not drift with the session. It stays anchored to observed scan outcomes.
It does not get smarter every time. It builds calibration signal every time. That is a more accurate claim, and the distinction matters.
What the Skill Does

Install:
cp -r claude-skills/slop-detector ~/.claude/skills/slop-detector
# restart Claude Code
Four slash commands become available:
| Command | What it does |
|---|
/slop | Full project scan — interprets findings, prioritizes fixes, proposes patch plan |
/slop-file [path] | Per-file deep-dive — explains each metric, gives concrete fix per pattern |
/slop-gate | Hard gate decision — PASS or FAIL, lists blocking files with deficit_score >= 70 |
/slop-spar | Adversarial validation — probes metric boundaries, catches calibration drift |
The intended workflow inside a Claude session:
1. /slop → baseline scan, identify top offenders
2. review findings → Claude prioritizes by deficit_score
3. patch files → fix patterns with Claude's help
4. /slop-file <path> → verify improvement per file
5. /slop → confirm project aggregate improved
6. /slop-gate → gate decision before merge
Quality policy lives in the skill layer. You do not re-explain what CRITICAL_DEFICIT means or which patterns are critical on every session.
The LEDA Flywheel
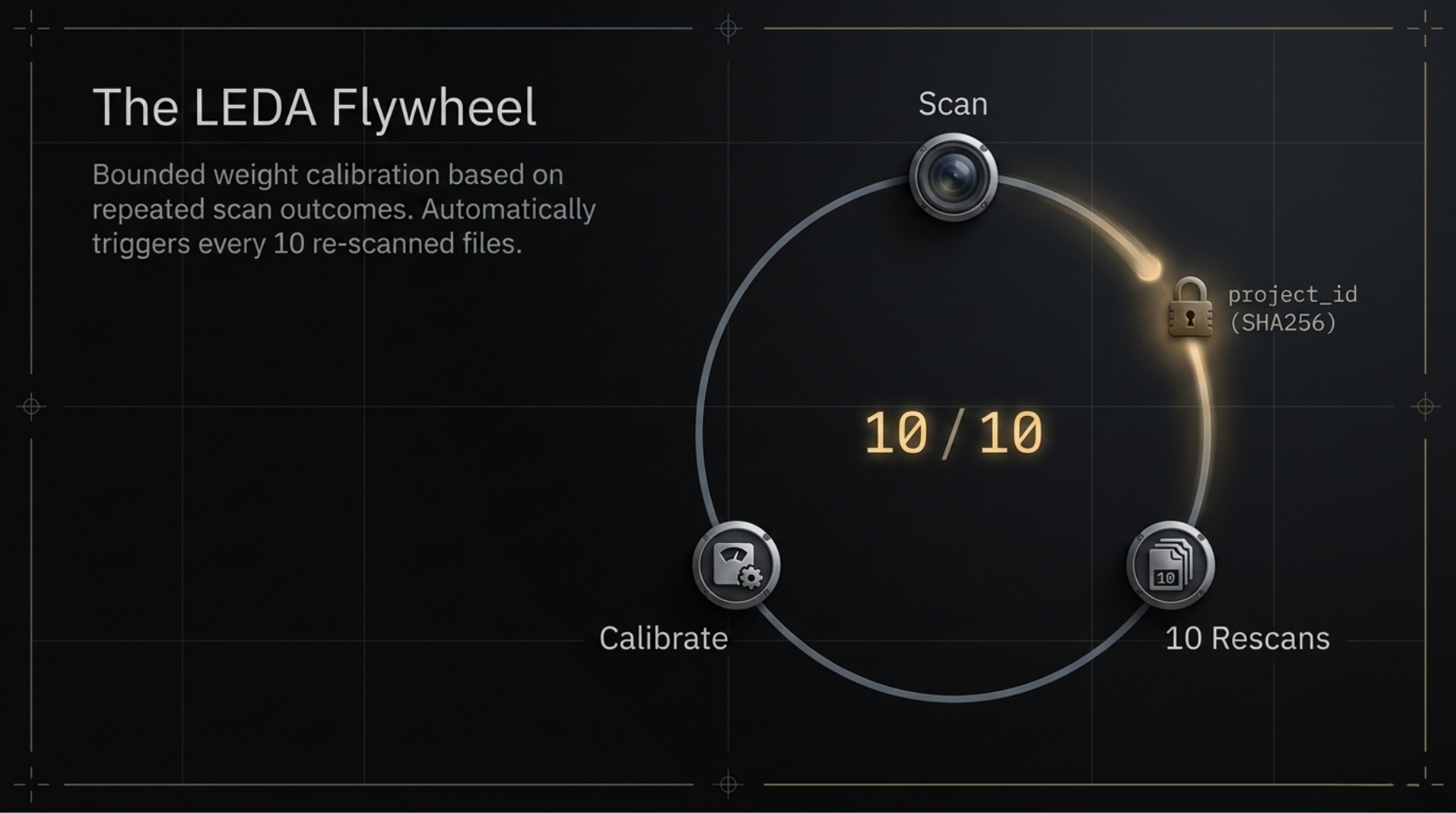
This is the part that matters.
LEDA is not model retraining. It is bounded weight calibration based on repeated scan outcomes.
/slop runs slop-detector --project . --json — without --no-history. Every invocation auto-records results to ~/.slop-detector/history.db, tagged with a project_id (sha256 of cwd) so signals never mix across different repositories.
After every 10 re-scanned files, the tool runs the LEDA self-calibration loop automatically:
/slop called
│
├─► scan result → recorded to history.db (project-scoped)
│
├─► 10 re-scanned files milestone?
│ └─► SelfCalibrator: 4D grid-search over run history
│ (ldr × inflation × ddc × purity weights)
│ └─► confidence gap > 0.10?
│ └─► .slopconfig.yaml updated silently
│
└─► next /slop → calibrated weights, sharper detection
The calibrator uses re-scanned files as signal — not raw record count. A file counts toward the milestone only when the tool has seen it improve or degrade across at least two runs. This prevents first-time project scans from triggering calibration on noise.
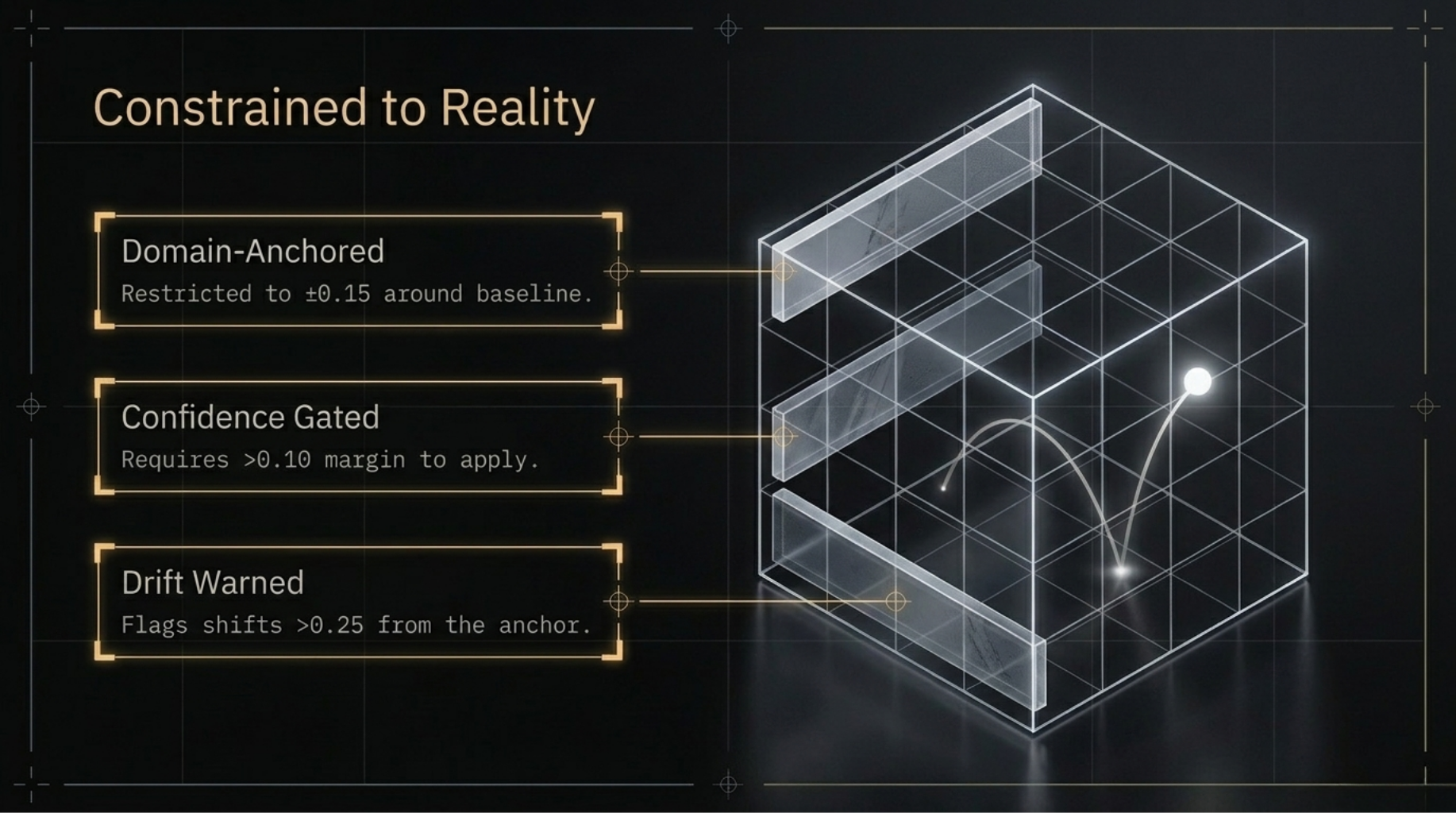
Three constraints keep calibration bounded:
- Domain-anchored — grid search is constrained to ±0.15 around domain baseline weights. Detection cannot drift outside the meaningful range for your project type.
- Confidence gate — only applies when the top candidate weight set beats the second by > 0.10. Ambiguous signals produce no change.
- Drift warnings —
CalibrationResult.warnings flags any dimension that shifted > 0.25 from the anchor.
/slop-spar adds a separate adversarial layer: it probes known-pattern anchors, metric boundary cases, and existence conditions. When it detects that measured behavior has diverged from metric claims, it recommends --self-calibrate --apply-calibration explicitly.
What the Data Shows — and What We Won't Claim
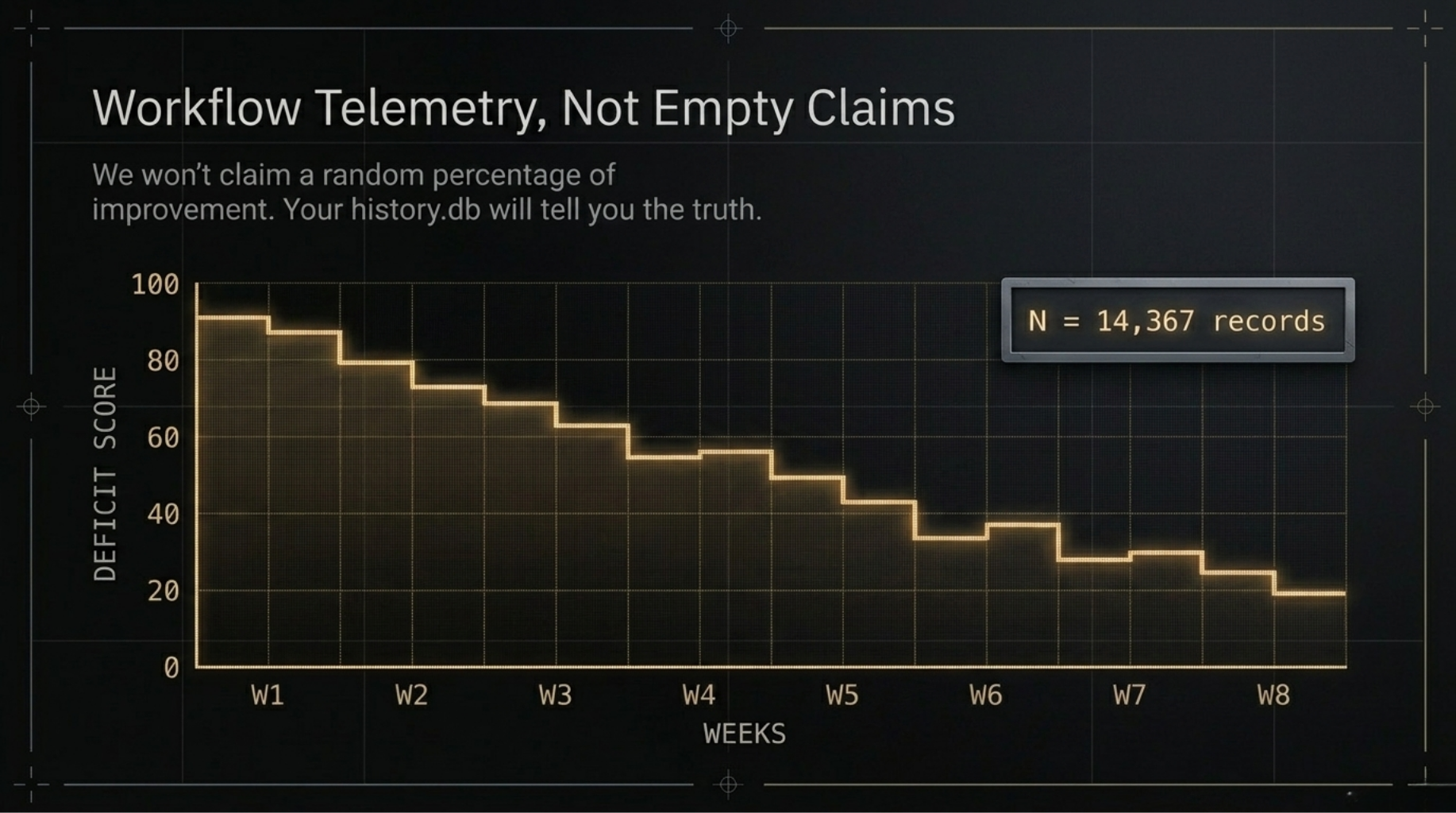
We will not tell you that AI-SLOP Detector improves code quality by X%.
We have not run a controlled study. We have not compared matched projects with and without the tool. Any number we put here would be a claim we cannot prove, and this tool is built specifically to catch that kind of thing.
What we do have: the tool scanning itself. Every time a core module was changed, it got re-scanned. N = 14,367 records across all projects in ~/.slop-detector/history.db.
This is not outcome evidence. It is workflow telemetry. Here is what the scan history shows for the eight most-improved files in this codebase:
File Scans Worst → Best Improvement
─────────────────────────────────────────────────────────
ddc.py 86 87.8 → 11.0 -76.8 pts
placeholder.py 92 70.3 → 0.0 -70.3 pts
cross_file.py 89 70.3 → 5.0 -65.3 pts
ci_gate.py 88 69.3 → 6.2 -63.1 pts
cli.py 88 68.4 → 8.4 -60.0 pts
ldr.py 90 58.0 → 0.1 -57.9 pts
python_advanced.py 95 74.0 → 18.0 -55.9 pts
context_jargon.py 86 55.7 → 5.0 -50.7 pts
─────────────────────────────────────────────────────────
Source: self-scan, history.db — not an independent study
And the weekly project aggregate (avg deficit score):
Week Avg Deficit Critical Files Note
────────────────────────────────────────────────────────
2026-W09 11.9 3 baseline
2026-W10 22.1 20 structural refactor spike
2026-W14 20.0 58 large feature addition
2026-W15 11.9 14 post-refactor recovery
2026-W17 12.2 13 current — stable CLEAN state
────────────────────────────────────────────────────────
The mechanism is not mysterious. Scan reveals structural problems → Claude sees exact pattern names and line references → Claude (or the developer) fixes them → rescan confirms improvement → LEDA registers the delta and adjusts detection weights accordingly.
The loop does not guarantee quality. It makes quality visible, then measurable, then improvable.
Whether that loop improves your codebase is something your history.db will tell you — not us.
Also in v3.6.0
CI gate exit code fix. --ci-mode hard without --ci-report was returning exit 0 even on CRITICAL_DEFICIT files — a two-line fix in _evaluate_ci_gate() (commit 0d67997). This affected v3.1.1 through v3.5.0 on the specific path of using the gate without the reporting flag. A regression test at the subprocess level was added to prevent recurrence (commit 0208af4).
Pre-commit hooks rewritten. Three hook variants now use python -m slop_detector.cli as entry point (bypasses Windows .exe wrapper exit-code issue), and --severity high (nonexistent flag) replaced with --ci-mode:
repos:
- repo: https://github.com/flamehaven01/AI-SLOP-Detector
rev: v3.6.0
hooks:
- id: slop-detector # hard gate
# - id: slop-detector-warn # report only
# - id: slop-detector-patterns # fast per-file
VS Code Extension v3.6.0. Version tracks core library. No behavior changes from v3.5.0.
The Shape of the Loop

The skill + LEDA loop is the external reference point. Detection weights stay grounded in observed scan outcomes — files that improved across re-scans, files that stayed problematic — rather than in what the assistant believes is correct at any given moment.
The loop does not guarantee quality. It makes quality visible, then measurable, then improvable.
We won't tell you what percentage your code will improve. That would make us the thing we are trying to detect.
The scanner is not Claude's opinion about code quality. It is a measurement that gets calibrated against reality, session by session. Your history.db will tell you the rest.

Links: